Knowledge Transfer
Ethickfox kb page with all notes
Project maintained by ethickfox Hosted on GitHub Pages — Theme by mattgraham
DB
Cовокупность данных, хранимых в соответствии со схемой данных, манипулирование которыми выполняют в соответствии с правилами средств моделирования данных
СУБД
Комплекс программ, позволяющих создать базу данных и манипулировать данными . Система обеспечивает безопасность, надёжность хранения и целостность данных, а также предоставляет средства для администрирования БД.Состоит из:
- ядро, которое отвечает за управление данными во внешней и оперативной памяти и журнализацию;
- процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода;
- подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД;
- сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
По типу делятся на:
- Иерархические
- Сетевые
- Реляционные
- Объектно-ориентированные
- Объектно-реляционные
Схема
Представляет собой пространство имён: она содержит именованные объекты (таблицы, типы данных, функции и операторы), имена которых могут совпадать с именами других объектов, существующих в других схемах.
Пользователь
Лицо, которое имеет набор прав для подключения и работы с бд.
Нормализация
Приведение отношений между таблицами к нормальному виду. Целью является исключение дублирования данных:
- 1НФ - все столбцы содержат только скалярные значения
- 2НФ - каждый неключевой атрибут неприводимо зависит от Первичного Ключа(ПК)
- 3НФ - каждый неключевой атрибут нетранзитивно зависит от первичного ключа.
- 4НФ - нетривиальные многозначные зависимости фактически являются функциональными зависимостями от ее потенциальных ключей
- 5НФ - отсутствуют сложные зависимые соединения между атрибутами
Денормализация - процесс помещения избыточных данных в таблицу с целью повышения производительности
Аномалии
называется такая ситуация в таблице БД, которая приводит к противоречию в БД либо существенно усложняет обработку БД. Причиной является излишнее дублирование данных в таблице, которое вызывается наличием функциональных зависимостей от не ключевых атрибутов.
Аномалии-модификации
Изменение одних данных может повлечь просмотр всей таблицы и соответствующее изменение некоторых записей таблицы.
Аномалии-удаления
При удалении какого либо кортежа из таблицы может пропасть информация, которая не связана напрямую с удаляемой записью.
Аномалии-добавления
Информацию в таблицу нельзя поместить, пока она не полная, либо вставка записи требует дополнительного просмотра таблицы.
Операторы SQL
DML
Data Manipulation Language - команды для работы с данными в таблицах
-
SELECT
-
INSERT
-
Простая вставка
-
Для всех значений
NSERT INTO people VALUES (8,'Oleg','1990-03-14',190);
-
Для определенных
INSERT INTO people (firstname, birthday, car_id) VALUES ('Maksim','1999-03-14',2);
-
С функциями
INSERT INTO people (firstname, birthday, car_id) VALUES (INITCAP('Maksim'),TO_DATE('1999-03-14',’YYYY-MM-DD’),2);
-
С подзапросом, Values не нужны
INSERT INTO people (firstname, birthday, car_id)
-
(select firstname, birthday, car_id from people);
-
-
UPDATE
-
Изменение значения в одной строке
-
UPDATE people SET weight = 59, car_id=1 where id=3;
-
Изменение значения в нескольких строках
-
UPDATE people SET weight = 59, car_id=1 where weight < 100;
-
Изменение значения во всех строках
-
UPDATE people SET weight = 59, car_id=1;
-
С подзапросом
-
Для поиска
UPDATE people SET weight=1000 where car_id in (select id from cars where cars.brand='lada');
-
Для значения
UPDATE people SET weight=(select max(weight) from people) where car_id=2;
-
-
DELETE
- Удалить одну строку из таблицы
- DELETE from people where id=3;
- Удалить несколько строк из таблицы
- DELETE from people where car_id=2;
- Удалить все строки
- DELETE from people;
- Удалить с подзапросом
- DELETE from people where id = (select id from people where weight = 99);
DDL
Data Definition Language - команды для работы со структурой таблицы. Пока транзакция открыта, DDL команда не может выполниться. Он быстрее DML.
- CREATE
- ALTER - изменение таблицы
- DROP - удаление таблицы со всеми данными
- RENAME
- TRUNCATE - удаление внутренностей, но сама таблица остается
TCL
Transaction Control Language - команды для управления транзакциями
- COMMIT - подтверждение изменений
- ROLLBACK - отмена изменений
- SAVEPOINT - точка сохранения
Join
- Natural join- автоматическое объединение по общему столбцу(столбцам), либо если нет, то будет Cross Join
select * from cars natural join work natural join people;
-
Cross join - декартово произведение. Перемножаются все строки из таблиц
-
select * from people CROSS JOIN cars order by firstname;
-
-
Outer join
-
LEFT OUTER JOIN - всё пересечение, плюс то, что входит только в левую таблицу
-
select * from people LEFT OUTER JOIN cars c on people.car_id = c.id
-
-
RIGHT OUTER JOIN - всё пересечение, плюс то, что входит только в правую таблицу
-
select * from people Right OUTER JOIN cars c on people.car_id = c.id
-
-
FULL OUTER JOIN - всё пересечение, плюс то, что входит только в правую таблицу и то, что входит только в левую
-
select * from people FULL OUTER JOIN cars c on people.car_id = c.id
-
-
-
inner join
- USING - объединение по столбцу/цам с одинаковым названием
- select * from people join cars using(id);
- ON - объединение по столбцу/цам с разными названиями
- EQUIJOIN
- select * from people join cars c on car_id = c.id;
- NONEQUIJOIN
- select * from people join cars c on car_id != c.id
- Self Join
- select * from people join people p on people.car_id = p.id;





SET OPERATORS
производят операции над множествами и возвращают одно
UNION is a type of operator/clause in SQL, that works similar to the union operator in relational algebra. It does nothing more than just combining information from multiple tables that are union compatible.
The tables are said to be union compatible if they follow the conditions given below −
- The tables to be combined must have same number of columns with the same datatype.
- The number of rows need not be same.
UNION - объединение с сортировкой и без дубликатов
select p1.weight from people p1 union
select p1.weight from people p1

UNION ALL - объединение с дубликатами
select max(p1.weight) from people p1
union all
select min(p1.weight) from people p1

select p1.weight from people p1 union all
select p1.weight from people p1

INTERSECT - общие значения в множествах
select p1.weight from people p1 intersect
select p1.weight from people p1
EXCEPT - строки из первого множества, которых нет во втором
select p1.weight from people p1 except
select p1.weight from people p1

| SQL JOIN | SQL UNION |
| The SQL JOIN is used when we have to extract data from more than one table. | The SQL UNION is used when we have to display the results of two or more SELECT statements. |
| In the case of SQL JOINS, the records are combined into new columns. | In the case of SQL UNION, the records are combined into new rows. |
| The SQL JOINS facilitates the joining of tables vertically. | The SQL UNION facilitates the connection of tables vertically. |
| The SQL JOINS are used to produce the given table's intersection. | The SQL UNION is used to produce the given table's conjunction. |
| The duplicate values can exist in SQL JOINS. | The duplicate values are removed by default in SQL UNION |
| To use SQL JOINS the two given tables need to have at least one column present within them. | To use SQL UNION the domain of the columns along with their attributes needs to be the same. |
Constraint
Ограничения для столбцов в создаваемой таблице
- NOT NULL
- PRIMARY KEY
- FOREIGN KEY
- ON DELETE CASCADE
- ON DELETE SET NULL
- CHECk
- UNIQUE
- EXCLUDE
GROUP BY
По одному столбцу
select birthday, count(*) from people
group by birthday
order by birthday;
По нескольким столбцам
select birthday,firstname, count(*) num from people
group by birthday, firstname
order by num desc ;
HAVING
условия для group функций (в where их нельзя использовать)
select birthday, avg(weight), count(*) from people
group by birthday
having avg(weight) > 60;
Tablespace
DataFiles
Partition
Масштабирование баз данных
Репликация
Репликация позволяет создать полный дубликат базы данных. Так, вместо одного сервера у Вас их будет несколько:
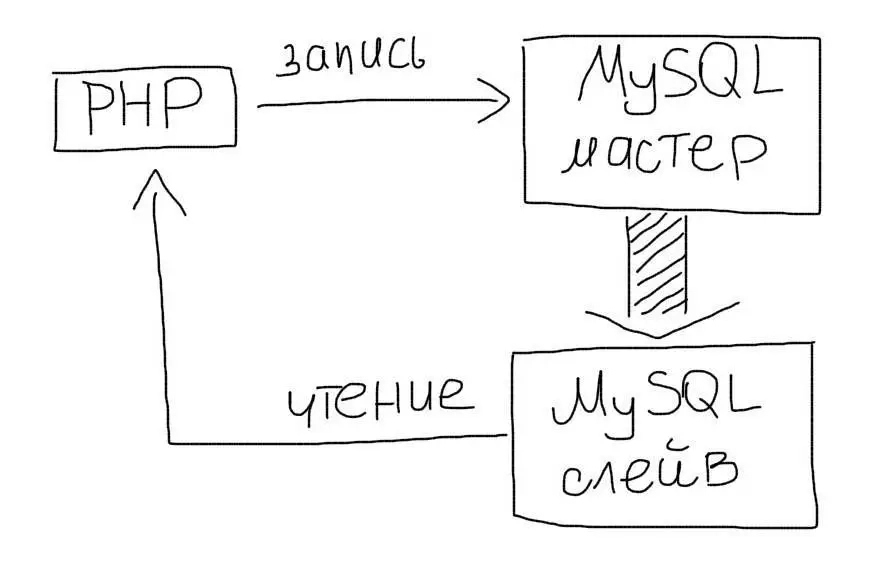
Master-slave
Чаще всего используют схему master-slave:
- Master — это основной сервер БД, куда поступают все данные. Все изменения в данных (добавление, обновление, удаление) должны происходить на этом сервере.
- Slave — это вспомогательный сервер БД, который копирует все данные с мастера. С этого сервера следует читать данные. Таких серверов может быть несколько.
Репликация позволяет использовать два или больше одинаковых серверов вместо одного. Операций чтения (SELECT) данных часто намного больше, чем операций изменения данных (INSERT/UPDATE). Поэтому, репликация позволяет разгрузить основной сервер за счет переноса операций чтения на слейв.
Следует отметить, что репликация сама по себе не очень удобный механизм масштабирования. Причиной тому — рассинхронизация данных и задержки в копировании с мастера на слейв. Зато это отличное средство для обеспечения отказоустойчивости. Вы всегда можете переключиться на слейв, если мастер ломается и наоборот. Чаще всего репликация используется совместно с шардингом именно из соображений надежности.
Шардинг
Шардинг (иногда шардирование) — это другая техника масштабирования работы с данными. Суть его в разделении (партиционирование) базы данных на отдельные части так, чтобы каждую из них можно было вынести на отдельный сервер. Этот процесс зависит от структуры Вашей базы данных и выполняется прямо в приложении в отличие от репликации:
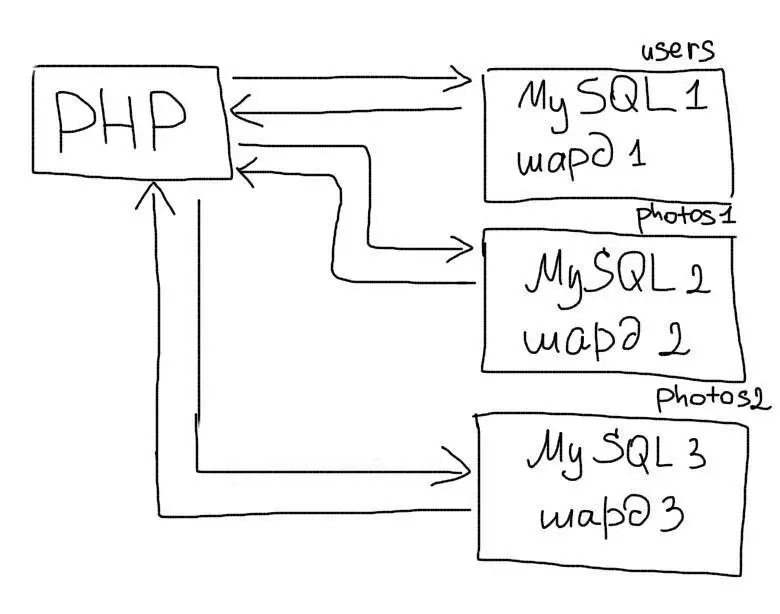
Вертикальный шардинг
Вертикальный шардинг — это выделение таблицы или группы таблиц на отдельный сервер. Например, в приложении есть такие таблицы:
- users — данные пользователей
- photos — фотографии пользователей
- albums — альбомы пользователей
Таблицу users Вы оставляете на одном сервере, а таблицы photos и albums переносите на другой. В таком случае в приложении Вам необходимо будет использовать соответствующее соединение для работы с каждой таблицей
Горизонтальный шардинг
Горизонтальный шардинг — это разделение одной таблицы на разные сервера. Это необходимо использовать для огромных таблиц, которые не умещаются на одном сервере. Разделение таблицы на куски делается по такому принципу:
- На нескольких серверах создается одна и та же таблица (только структура, без данных).
- В приложении выбирается условие, по которому будет определяться нужное соединение (например, четные на один сервер, а нечетные — на другой).
- Перед каждым обращением к таблице происходит выбор нужного соединения.
Допустим, наше приложение работает с огромной таблицей, которая хранит фотографии пользователей. Мы подготовили два сервера (обычно они называются шардами) для этой таблицы. Для нечетных пользователей мы будем работать с первыми сервером, а для четных — со вторым. Таким образом, на каждом из серверов будет только часть всех данных о фотках пользователей.
Round robing
Хранение данных
Объекты в бд
User/Roles - пользователи с различным набором прав на работу с бд
Schema - пространство имен: она содержит именованные объекты (таблицы, типы данных, функции и операторы), имена которых могут совпадать с именами других объектов, существующих в других схемах.
Table
View - специальное представление данных, которое может быть выражено, как часть таблицы или объединение нескольких
create view people_weight as (select firstname, weight from people);
select * from people_weight;
Simple - одна таблица, нет функций, нет агрегации
Есть обратная связь - можно использовать DML
Complex - несколько таблиц, функции, агрегация
Нет обратной связи - нельзя использовать DML
with
check option
read only
Index
Sequence - последовательность для создания индексов. Никак не зависит от транзакции, изменится без коммита
CREATE sequence s2 INCREMENT BY 1 MINVALUE 10 MAXVALUE 20 CYCLE OWNED BY people_car_id_seq.cache_value;
intersect - возвращает совпадающие результаты из 2-х селектов
except - возвращает результаты из первого селект, которые не содержатся во втором
exists - проверяет, что подзапрос возвращает хотя бы одну строку
Агрегатная функция - информация из нескольких строк таблицы - один результат
Sql-инъекции - это передача данных в запрос, содержащие экранирующие символы, изменяющие изначальный запрос. В Hibernate для обработки существуют Prepared Statement
Index
- Copy of information from a table
- Smaller than a table
- Presorted
Types
- Clustered
- Determines how a table is written to disk
- Only one per table
- Automatically created with a primary key
- Nonclustered
- Most common type
- Up to 999 per table in SQL Server 2016
- Columnstore
- Converts column data into rows
- Spatial
- Used with spatial data types: geometry and geography
- • Specialized GIS systems
- XML
- Converts XML data into tabular format
- Two types: primary and secondary
- Full-text
- Supports English language queries
Index types
-
Single Column
CREATE INDEX index_name ON table_name (column_name); -
MultiColumn
CREATE INDEX index_name ON table_name (column1_name, column2_name); -
Unique
A unique index does not allow any duplicate values to be inserted into the table.CREATE UNIQUE INDEX index_name on table_name (column_name); -
Partial
A partial index is an index built over a subset of a table; the subset is defined by a conditional expressionCREATE INDEX index_name on table_name (conditional_expression); -
Implicit
Implicit indexes are indexes that are automatically created by the database server when an object is created. Indexes are automatically created for primary key constraints and unique constraints.
When not to use
- Indexes should not be used on small tables.
- Tables that have frequent, large batch update or insert operations.
- Indexes should not be used on columns that contain a high number of NULL values.
- Columns that are frequently manipulated should not be indexed.
Транзакции
Ряд действий, выполняемых подряд, которые должны быть обработаны полностью, или в случае сбоя БД быть восстановлены до состояния, пока транзакция не началась. Транзакция запускается при первой DML команде.
Условия закрытия транзакции:
- явный commit или rollback
- DDL транзакция (закрывает с помощью commit)
- Сессия закрыта (закрывает с помощью rollback)
Команды:
Commit - подтверждение изменений в транзакции
commit;
Rollback - отмена изменений в транзакции
Всей транзакции - завершает транзакцию
rollback;
До savepoint - не завершает транзакцию
rollback to savepoint save_point_name;
Savepoint
savepoint save_point_name;
AutoCommit -автоматическое выполнение DML команд
set AUTOCOMMIT = ON;
SELECT FOR UPDATE - блокирует таблицу для изменений(ставит Lock ), пока не будет завершена текущая транзакция
select * from people for update;
ACID
Atomicity
Атомарность - либо все команды в транзакции срабатывают, либо все отменяется.
Consistency
согласованность - означает что все требования уникальности были соблюдены для каждой совершенной транзакции. Данные будут корректны в соответствии со всеми предопределенными правилами, ограничениями, каскадами и триггерами, примененными к БД.
Isolation
изолированность - все транзакции будут выполняться изолированно. До подтверждения транзакции измененные данные видны только в текущей сессии
Durability
долговечность - когда транзакция будет применена, она останется в системе, даже если БД упала сразу после выполнения этой транзакции. Любые изменения, внесенные транзакцией, должны оставаться навсегда.
Изолированность
На сколько сильно друг на друга влияют транзакции.Выбирая уровень транзакции, мы пытаемся прийти к консенсусу в выборе между высокой согласованностью данных между транзакциями и скоростью выполнения этих самых транзакций.
This property ensures that multiple transactions can occur concurrently without leading to the inconsistency of the database state. Transactions occur independently without interference. Changes occurring in a particular transaction will not be visible to any other transaction until that particular change in that transaction is written to memory or has been committed. This property ensures that the execution of transactions concurrently will result in a state that is equivalent to a state achieved these were executed serially in some order.
Transaction Isolation Levels
Transaction isolation levels are a measure of the extent to which transaction isolation succeeds. In particular, transaction isolation levels are defined by the presence or absence of the following phenomena:
- Dirty Reads A dirty read occurs when a transaction reads data that has not yet been committed. For example, suppose transaction 1 updates a row. Transaction 2 reads the updated row before transaction 1 commits the update. If transaction 1 rolls back the change, transaction 2 will have read data that is considered never to have existed.
- Nonrepeatable Reads A nonrepeatable read occurs when a transaction reads the same row twice but gets different data each time. For example, suppose transaction 1 reads a row. Transaction 2 updates or deletes that row and commits the update or delete. If transaction 1 rereads the row, it retrieves different row values or discovers that the row has been deleted.
- Phantoms A phantom is a row that matches the search criteria but is not initially seen. For example, suppose transaction 1 reads a set of rows that satisfy some search criteria. Transaction 2 generates a new row (through either an update or an insert) that matches the search criteria for transaction 1. If transaction 1 reexecutes the statement that reads the rows, it gets a different set of rows.
The four transaction isolation levels (as defined by SQL-92) are defined in terms of these phenomena. In the following table, an "X" marks each phenomenon that can occur.
| Transaction isolation level | Dirty reads | Nonrepeatable reads | Phantoms |
| Read uncommitted | X | X | X |
| Read committed | -- | X | X |
| Repeatable read | -- | -- | X |
| Serializable | -- | -- | -- |
The following table describes simple ways that a DBMS might implement the transaction isolation levels.
Read uncommitted
Самый низкий уровень изоляции, каждая транзакция видит незафиксированные изменения другой транзакции. При откате изменений другой транзакции, в этой окажутся ошибочные данные. Это феномен грязного чтения
Transactions are not isolated from each other. If the DBMS supports other transaction isolation levels, it ignores whatever mechanism it uses to implement those levels. So that they do not adversely affect other transactions, transactions running at the Read Uncommitted level are usually read-only.
Read commited
Параллельно выполняющиеся транзакции видят только зафиксированные изменения из других транзакций. После коммита мы видим удаленные и обновленные строки - это феномен неповторяющегося чтения и феномен чтения фантомов - когда видим новые добавленные
https://miro.medium.com/v2/resize:fit:1100/format:webp/1*8E13WT_TotPkxV4ug3dFiQ.png
{kind=link}
The transaction waits until rows write-locked by other transactions are unlocked; this prevents it from reading any "dirty" data.
The transaction holds a read lock (if it only reads the row) or write lock (if it updates or deletes the row) on the current row to prevent other transactions from updating or deleting it. The transaction releases read locks when it moves off the current row. It holds write locks until it is committed or rolled back.
Repeatable read
Уровень, позволяющий предотвратить неповторяющееся чтение. В исполняющейся транзакции мы не видим изменения и удаления другими транзакциями. Но фантомное чтение не уходит
The transaction waits until rows write-locked by other transactions are unlocked; this prevents it from reading any "dirty" data.
The transaction holds read locks on all rows it returns to the application and write locks on all rows it inserts, updates, or deletes. For example, if the transaction includes the SQL statement
SELECT * FROM Orders, the transaction read-locks rows as the application fetches them. If the transaction includes the SQL statement
DELETE FROM Orders WHERE Status = 'CLOSED', the transaction write-locks rows as it deletes them.
Because other transactions cannot update or delete these rows, the current transaction avoids any nonrepeatable reads. The transaction releases its locks when it is committed or rolled back.
Serializable
Уровень, при котором транзакции ведут себя так, как будто кроме них ничего нет. Избавляет от фантомного чтения
The transaction waits until rows write-locked by other transactions are unlocked; this prevents it from reading any "dirty" data.
The transaction holds a read lock (if it only reads rows) or write lock (if it can update or delete rows) on the range of rows it affects. For example, if the transaction includes the SQL statement
SELECT * FROM Orders
, the range is the entire Orders table; the transaction read-locks the table and does not allow any new rows to be inserted into it. If the transaction includes the SQL statement
DELETE FROM Orders WHERE Status = 'CLOSED'
, the range is all rows with a Status of "CLOSED"; the transaction write-locks all rows in the Orders table with a Status of "CLOSED" and does not allow any rows to be inserted or updated such that the resulting row has a Status of "CLOSED".
Because other transactions cannot update or delete the rows in the range, the current transaction avoids any nonrepeatable reads. Because other transactions cannot insert any rows in the range, the current transaction avoids any phantoms. The transaction releases its lock when it is committed or rolled back.
Изолированности по умолчанию в БД
У всех по разному, у пг - read committed. Read uncommitted в пг даже нет
Database lock
When two sessions or users of database try to update or delete the same data in a table, then there will be a concurrent update problem. In order to avoid this problem, database locks the data for the first user and allows him to update/delete the data. Once he is done with his update/delete, he COMMITs or ROLLBACK the transaction, which will release the lock on the data. When lock on the data is released, another user can lock it for his changes. We are locking the data in database while updating to avoid concurrent update problem. Concurrent Update problem is the one where multiple sessions of the database is trying to update the same data at the same time
Locking techniques
- Database Level Locking : In this method, entire database is locked for update. Here, only one user or session will be active for any update and any other users cannot update the data. This method is not widely used, as it locks entire database. However, in Oracle the exclusive lock is same as Database lock and does not allow others to use entire database. It will be helpful when some support update is being executed like upgrading to new version of software etc.
- File Level Locking : Here, entire database file will be locked. When we say database file, it may include whole table, or part of a table or part of multiple tables. Since file lock can include either whole or partial data from different tables, this type of lock is less frequent.
- Table Level Locking : In this method, entire table will be locked. This will be useful when we need to update whole rows of the table. It will also be useful when we add/ remove some columns of the table where the changes affect entire table. Therefore, in Oracle this type of lock is also known as DDL lock.
- Page or Block Level Locking : In this method, page or block of the database file will be locked for update. A page or block might contain entire or partial data of the table. This page or block represents space in memory location where data is occupied. This may contain entire table data or partial data. Hence this type of locking is also less frequent.
- Row Level Locking : In this method entire row of a table is locked for update. It is most common type of locking mechanism.
- Column Level Locking : In this method some columns of a row of a table is locked for update. This type of lock requires lots of resource to manage and release locks. Hence it is very less frequently used locking type.
Whenever a user issues UPDATE or DELETE command, database will implicitly place the lock on the data. It does not require user to explicitly type lock on the data. Whenever the database sees UPDATE or DELETE statement, lock is automatically placed on the data. Reading the data when it is locked depends on the locking mechanism used. If the lock is read exclusive, then it will not allow to read locked data
Lock contention
Lock contention is the process where lock on the data will not be release as quickly as the COMMIT or ROLLBACK is issued. It might take time to release the lock due to slower systems, or may be another lock on another data is waiting for it to release the lock. This will make the system to wait for release the lock for indefinite period of time. This will lead to deadlock situation.
Lock escalation
Lock escalation is the process of escalating the locks to higher level due to extremely increasing locks at lower level. For example, if there are many locks at row level for a table, it will be better to escalate this lock to table level rather than having at each row level. This will help in reducing the overhead of maintaining the locks for each row. It reduces the number of locks on the table and increases the performance drastically
Deadlock Avoidance
always access the tables in the same order. In this way, in the scenario described above, Transaction T1 simply waits for transaction T2 to release the lock on Grades before it begins. When transaction T2 releases the lock, Transaction T1 can proceed freely.
Another method for avoiding deadlock is to apply both row-level locking mechanism and READ COMMITTED isolation level. However, It does not guarantee to remove deadlocks completely.
Deadlock Detection
When a transaction waits indefinitely to obtain a lock, The database management system should detect whether the transaction is involved in a deadlock or not. Wait-for-graph is one of the methods for detecting the deadlock situation. This method is suitable for smaller databases. In this method, a graph is drawn based on the transaction and their lock on the resource. If the graph created has a closed-loop or a cycle, then there is a deadlock.
Deadlock prevention
For a large database, the deadlock prevention method is suitable. A deadlock can be prevented if the resources are allocated in such a way that deadlock never occurs. The DBMS analyzes the operations whether they can create a deadlock situation or not, If they do, that transaction is never allowed to be executed. Deadlock prevention mechanism proposes two schemes :
- Wait-Die Scheme – In this scheme, If a transaction requests a resource that is locked by another transaction, then the DBMS simply checks the timestamp of both transactions and allows the older transaction to wait until the resource is available for execution. Suppose, there are two transactions T1 and T2, and Let the timestamp of any transaction T be TS (T). Now, If there is a lock on T2 by some other transaction and T1 is requesting for resources held by T2, then DBMS performs the following actions: Checks if TS (T1) < TS (T2) – if T1 is the older transaction and T2 has held some resource, then it allows T1 to wait until resource is available for execution. That means if a younger transaction has locked some resource and an older transaction is waiting for it, then an older transaction is allowed to wait for it till it is available. If T1 is an older transaction and has held some resource with it and if T2 is waiting for it, then T2 is killed and restarted later with random delay but with the same timestamp. i.e. if the older transaction has held some resource and the younger transaction waits for the resource, then the younger transaction is killed and restarted with a very minute delay with the same timestamp.
This scheme allows the older transaction to wait but kills the younger one.
- Wound Wait Scheme – In this scheme, if an older transaction requests for a resource held by a younger transaction, then an older transaction forces a younger transaction to kill the transaction and release the resource. The younger transaction is restarted with a minute delay but with the same timestamp. If the younger transaction is requesting a resource that is held by an older one, then the younger transaction is asked to wait till the older one releases it.
| Wait – Die | Wound -Wait |
| It is based on a non-preemptive technique. | It is based on a preemptive technique. |
| In this, older transactions must wait for the younger one to release its data items. | In this, older transactions never wait for younger transactions. |
| The number of aborts and rollback is higher in these techniques. | In this, the number of aborts and rollback is lesser. |
How to Perform Database Monitoring
Common approaches to database monitoring can be divided into two groups:
- proactive - try to identify warning signs before they become full-blown problems
- reactive - alleviating the harm caused by existing problems
Key Metrics to Track
- Query Execution Performance
- Hardware
- Lack of memory
- Insufficient processing power
- Lack of free space in the disk
- Misconfigured disks
- Concurrency Problems - When many users access your database simultaneously, you might experience conflicts in queries and other activities. Slow queries can cause page locking. Batch activities might cause resource contention. All these problems can negatively impact the performance of your database.
Database Monitoring Best Practices
- Monitor Changes to the Database - A new application version often causes many changes to the database, which involves adding, changing or dropping database objects. It’s essential to monitor such changes, since these new or modified objects can cause performance issues.
- Measure Throughput - Throughput metrics, such as replication latency, are crucial for creating comparative baselines you can use to quickly identify anomalies. By closely following these metrics, you can identify their normal value. Afterward, you’ll be able to compare this baseline value with current metrics, allowing you to identify suspicious deviations.
- Monitor Availability and Consumption of Resources This practice is two-fold. It consists of verifying the database is online and checking the consumption of resources. How is CPU usage? How is memory usage? Is the disk close to being full?
- Track Database Logs - Collecting and monitoring database logs is essential if you want to practice proactive monitoring. These logs contain critical information you don’t typically find in general performance metrics, such as the time it took for each query in the database to run.
Example of tools
- SQL Power Tools
- Datadog
- SolarWinds
Explain Query
EXPLAIN SELECT * FROM gfgtable;