Knowledge Transfer
Ethickfox kb page with all notes
Project maintained by ethickfox Hosted on GitHub Pages — Theme by mattgraham
https://github.com/enhorse/java-interview
[!info] Top 133 Java Interview Questions Answers for 2 to 5 Years Experienced Programmers
A blog about Java, Programming, Algorithms, Data Structure, SQL, Linux, Database, Interview questions, and my personal experience.
https://javarevisited.blogspot.com/2015/10/133-java-interview-questions-answers-from-last-5-years.html#axzz87MBt6KUn
Java
Core
Concurrency
Thread API
-
What are the different types of Thread Priorities in Java? And what is the default priority of a thread assigned by JVM?
There are a total of 3 different types of priority available in Java.
MIN_PRIORITY: It has an integer value assigned with 1.
MAX_PRIORITY: It has an integer value assigned with 10.
NORM_PRIORITY: It has an integer value assigned with 5.
In Java, Thread with MAX_PRIORITY gets the first chance to execute. But the default priority for any thread is NORM_PRIORITY assigned by JVM.
-
What are the different ways of threads usage?
- We can define and implement a thread in java using two ways:
- Extending the Thread class
classInterviewBitThreadExampleextendsThread{ publicvoidrun(){ System.out.println("Thread runs..."); } publicstaticvoidmain(String args[]){ InterviewBitThreadExample ib =new InterviewBitThreadExample(); ib.start(); } }- Implementing the Runnable interface
classInterviewBitThreadExampleimplementsRunnable{ publicvoidrun(){ System.out.println("Thread runs..."); } publicstaticvoidmain(String args[]){ Thread ib =new Thread(new InterviewBitThreadExample()); ib.start(); } }- Implementing a thread using the method of Runnable interface is more preferred and advantageous as Java does not have support for multiple inheritances of classes.
start()method is used for creating a separate call stack for the thread execution. Once the call stack is created, JVM calls therun()method for executing the thread in that call stack.
- We can define and implement a thread in java using two ways:
-
Thread Priority
You can prioritize a thread - a certain number, when larger - higher priority. Such threads will be executed first and will have more CPU time.
-
States of thread
- ==NEW== - when a new thread is created, it is in the new state. The thread has not yet started to run when the thread is in this state.
- ==RUNNABLE== - a thread that is ready to run is moved to a runnable state. In this state, a thread might actually be running or it might be ready to run at any instant of time.
- ==WAITING== - when a thread is temporarily inactive, then it’s in one of the following states: blocked or waiting.
- ==BLOCKED== - when a thread is temporarily inactive, then it’s in one of the following states: blocked or waiting.
- ==TIMED WAITING== - a thread lies in a timed waiting state when it calls a method with a time-out parameter. A thread lies in this state until the timeout is completed or until a notification is received.
- ==TERMINATED== - a thread terminates because of either of the following reasons:
- Because it exits normally. This happens when the code of thread has been entirely executed by the program.
- Because there occured some unusual erroneous event, like segmentation fault or an unhandled exception.
-
Why is synchronization necessary?
Concurrent execution of different processes is made possible by synchronization. When a particular resource is shared between many threads, situations may arise in which multiple threads require the same shared resource.
Synchronization assists in resolving the issue and the resource is shared by a single thread at a time. Let’s take an example to understand it more clearly. For example, you have a URL and you have to find out the number of requests made to it. Two simultaneous requests can make the count erratic.
No synchronization:
package anonymous; publicclassCounting { privateint increase_counter; publicintincrease() { increase_counter = increase_counter + 1; return increase_counter; } }
If a thread Thread1 views the count as 10, it will be increased by 1 to 11. Simultaneously, if another thread Thread2 views the count as 10, it will be increased by 1 to 11. Thus, inconsistency in count values takes place because the expected final value is 12 but the actual final value we get will be 11.
Now, the function increase() is made synchronized so that simultaneous accessing cannot take place.
With synchronization:
package anonymous; public class Counting { private int increase_counter; public synchronized int increase() { increase_counter = increase_counter + 1; return increase_counter; } }
If a thread Thread1 views the count as 10, it will be increased by 1 to 11, then the thread Thread2 will view the count as 11, it will be increased by 1 to 12. Thus, consistency in count values takes place.
-
What Is the Difference Between a Process and a Thread and a Task?
==Process== - object, which created by operating system, when user starts the application.
Processes do not share a common memory, while threads do.
==Thread== - for a single process, the operating system created one main thread, which completes commands from the central processor one by one.
To create new thread we can use class
Tread or class ExecutorService.
If an exception occurs in the thread that no one catches then it will terminate.
From the operating system’s point of view, a process is an independent piece of software that runs in its own virtual memory space.
The processes are thus usually isolated, and they cooperate by the means of inter-process communication which is defined by the operating system as a kind of intermediate API.
A task is simply a set of instructions loaded into the memory.
-
How Can You Create a Thread Instance and Run It?
To create an instance of a thread, you have two options. First, pass a Runnable instance to its constructor and call start(). Runnable is a functional interface, so it can be passed as a lambda expression:
Thread also implements Runnable, so another way of starting a thread is to create an anonymous subclass, override its run() method, and then call start():
-
Can you explain the Java thread lifecycle?
- New – When the instance of the thread is created and the start() method has not been invoked, the thread is considered to be alive and hence in the NEW state.
- Runnable – Once the start() method is invoked, before the run() method is called by JVM, the thread is said to be in RUNNABLE (ready to run) state. This state can also be entered from the Waiting or Sleeping state of the thread.
- Running – When the run() method has been invoked and the thread starts its execution, the thread is said to be in a RUNNING state.
- Non-Runnable (Blocked/Waiting) – When the thread is not able to run despite the fact of its aliveness, the thread is said to be in a NON-RUNNABLE state. Ideally, after some time of its aliveness, the thread should go to a runnable state.
- Blocked state if it wants to enter synchronized code but it is unable to as another thread is operating in that synchronized block on the same object. The first thread has to wait until the other thread exits the synchronized block.
- Waiting state if it is waiting for the signal to execute from another thread, i.e it waits for work until the signal is received.
- Terminated – Once the run() method execution is completed, the thread is said to enter the TERMINATED step and is considered to not be alive.

-
Compare the
sleep()andwait()methods in Java, including when and why you would use one vs. the other.sleep()is a blocking operation that keeps a hold on the monitor / lock of the shared object for the specified number of milliseconds.wait(), on the other hand, simply pauses the thread until either (a) the specified number of milliseconds have elapsed or (b) it receives a desired notification from another thread (whichever is first), without keeping a hold on the monitor/lock of the shared object.sleep()is most commonly used for polling, or to check for certain results, at a regular interval.wait()is generally used in multithreaded applications, in conjunction withnotify()/notifyAll(), to achieve synchronization and avoid race conditions. -
What Is the Difference Between the Runnable and Callable Interfaces? How Are They Used?
The Runnable interface has a single run method. It represents a unit of computation that has to be run in a separate thread. The Runnable interface does not allow this method to return value or to throw unchecked exceptions.
The Callable interface has a single call method and represents a task that has a value. That’s why the call method returns a value. It can also throw exceptions. Callable is generally used in ExecutorService instances to start an asynchronous task and then call the returned Future instance to get its value.
-
What Is a Daemon Thread, What Are Its Use Cases? How Can You Create a Daemon Thread?
A daemon thread is a thread that does not prevent JVM from exiting. When all non-daemon threads are terminated, the JVM simply abandons all remaining daemon threads. Daemon threads are usually used to carry out some supportive or service tasks for other threads, but you should take into account that they may be abandoned at any time.
-
What Is the Thread’s Interrupt Flag? How Can You Set and Check It? How Does It Relate to the Interruptedexception?
The interrupt flag, or interrupt status, is an internal Thread flag that is set when the thread is interrupted. To set it, simply call thread.interrupt() on the thread object_._
If a thread is currently inside one of the methods that throw InterruptedException (wait, join, sleep etc.), then this method immediately throws InterruptedException. The thread is free to process this exception according to its own logic.
If a thread is not inside such method and thread.interrupt() is called, nothing special happens. It is thread’s responsibility to periodically check the interrupt status using static Thread.interrupted() or instance isInterrupted() method. The difference between these methods is that the static Thread.interrupted() clears the interrupt flag, while isInterrupted() does not.
-
Async vs Concurrent vs Parallelism
Concurrency is a concept where several tasks appear to run simultaneously, but not necessarily in parallel. In a multithreaded process on a single processor, the processor can switch execution resources between threads, resulting in concurrent execution. Concurrency indicates that more than one thread is making progress, but the threads are not actually running simultaneously. The switching between threads happens quickly enough that the threads might appear to run simultaneously.
==Parallelism== - the method of execution different parts of same program at the same time. In the same multithreaded process in a shared-memory multiprocessor environment, each thread in the process can run concurrently on a separate processor, resulting in parallel execution, which is true simultaneous execution.
Asynchronous programming is a form of concurrency where tasks start and then move on without waiting for the previous task to finish. This can be achieved using callbacks, promises, futures, events, etc. Asynchronous operations might be carried out concurrently (in parallel) or might simply free up the main thread to do other tasks while the asynchronous task is waiting for some resource. Asynchronous programming can be achieved without multithreading
Multithreading is a form of concurrency where multiple threads (smallest unit of CPU execution) run in parallel on multi-core processors. is one method to achieve concurrency by running multiple threads in parallel. However, concurrency doesn’t always mean tasks run in parallel; it means they’re being managed in a way that they appear to be running at the same time. Multithreaded systems can be synchronous, where each thread waits for its operations to complete before moving on. However, in many modern systems, asynchrony and multithreading often go hand in hand, with asynchronous operations being offloaded to different threads to achieve parallelism.
-
Difference between optimistic and pessimistic concurrency models
Optimistic concurrency control is based on the idea of conflicts and transaction restart while pessimistic concurrency control uses locking as the basic serialization mechanism. Optimistic is more useful when transaction conflicts happen infrequently
-
What is Mutex?
Intrinsic locks in Java act as mutex (mutual exclusion locks), meaning that at most one thread can enter the lock. Mutex is not a class or interface in Java, but simply a general concept. Only two states are possible - "free" and "busy". Binary simaphor == mutex
-
What is Monitor?
Extra "superstructure" over the mutex. The term is also used to refer to a multithreaded design for controlling shared access to a shared resource ("object monitor"). For example, synchronized. The security mechanism creates the monitor! The compiler converts the word synchronized into several special pieces of code.
It involves a conditional variable and two operations - to wait for the condition and signal the occurrence of the condition. When the condition is met, only one task from the pool of tasks waiting for this condition to occur starts to run.
-
Threads vs Virtual Threads?
Thread is managed and scheduled by the operating system, to create a new kernel thread, we must do a system call, and that’s a costly operation.
While a virtual thread is managed and scheduled by a virtual machine. Their allocation doesn’t require a system call, and they’re free of the operating system’s context switch. Furthermore, virtual threads run on the carrier thread, which is the actual kernel thread used under-the-hood. As a result, since we’re free of the system’s context switch, we could spawn many more such virtual threads. Virtual threads is that they don’t block our carrier thread. With that, blocking a virtual thread is becoming a much cheaper operation, as the JVM will schedule another virtual thread, leaving the carrier thread unblocked.
-
Which types of threads do we have?
- User
- Daemon
-
How we could run a Thread?
==Runnable== - is an interface that has one unrealised method ==run==(). The interface is used by Thread class to perform a task in a separate thread.
==Callable== - the same as Runnable, but there is a generic for returning a result of a certain type.
==Executor== - is an interface that has a single execute method to submit Runnable instances for execution
-
What the purpose of Future Interface?
It performs some task with result at the end. Can be passed to the Thread or ExecutorService. Have get() method, which is the blocking one(will wait untill task is finished or cancelled)
-
What the purpose of CompletableFuture Class?
It can Invoke functions after completion, Accepts Runnable or Supplier.
- thenApply -
- thenAccept - execute consumer
- thenRun - runs some runnable
- Can be explicitly completed
-
What is ThreadLocal?
The TheadLocal construct allows us to store data that will be accessible only by a specific thread.
Let’s say that we want to have an Integer value that will be bundled with the specific thread:
ThreadLocal<Integer> threadLocalValue = new ThreadLocal<>();Next, when we want to use this value from a thread, we only need to call a get() or set() method. Simply put, we can imagine that ThreadLocal stores data inside of a map with the thread as the key.
As a result, when we call a get() method on the threadLocalValue, we’ll get an Integer value for the requesting thread:
threadLocalValue.set(1); Integer result = threadLocalValue.get();We can construct an instance of the ThreadLocal by using the withInitial() static method and passing a supplier to it:
ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 1);To remove the value from the ThreadLocal, we can call the remove() method:
When using ThreadLocal, we need to be very careful because every ThreadLocal instance is associated with a particular thread.
-
Using ThreadLocal with ThreadPool
ThreadLocal provides an easy-to-use API to confine some values to each thread. This is a reasonable way of achieving thread-safety in Java. However, we should be extra careful when we’re using ThreadLocals and thread pools together.
In order to better understand this possible caveat, let’s consider the following scenario:
- First, the application borrows a thread from the pool.
- Then it stores some thread-confined values into the current thread’s ThreadLocal.
- Once the current execution finishes, the application returns the borrowed thread to the pool.
- After a while, the application borrows the same thread to process another request.
- Since the application didn’t perform the necessary cleanups last time, it may re-use the same ThreadLocal data for the new request.
This may cause surprising consequences in highly concurrent applications.
One way to solve this problem is to manually remove each ThreadLocal once we’re done using it. Because this approach needs rigorous code reviews, it can be error-prone.
As it turns out, it’s possible to extend the ThreadPoolExecutor class and provide a custom hook implementation for the beforeExecute() and afterExecute() methods. The thread pool will call the beforeExecute() method before running anything using the borrowed thread. On the other hand, it’ll call the afterExecute() method after executing our logic.
public class ThreadLocalAwareThreadPool extends ThreadPoolExecutor { @Override protected void afterExecute(Runnable r, Throwable t) { // Call remove on each ThreadLocal } } -
Why wait, notify, and notifyAll methods are called from synchronized block or method in Java?
-
What is the
volatilekeyword? How and why would you use it?In Java, each thread has its own stack, including its own copy of variables it can access. When the thread is created, it copies the value of all accessible variables into its own stack. The
volatilekeyword basically says to the JVM “Warning, this variable may be modified in another Thread”.In all versions of Java, the
volatilekeyword guarantees global ordering on reads and writes to a variable. This implies that every thread accessing a volatile field will read the variable’s current value instead of (potentially) using a cached value.In Java 5 or later,
volatilereads and writes establish a happens-before relationship, much like acquiring and releasing a mutex.Using
volatilemay be faster than a lock, but it will not work in some situations. The range of situations in which volatile is effective was expanded in Java 5; in particular, double-checked locking now works correctly.The volatile keyword is also useful for 64-bit types like long and double since they are written in two operations. Without the volatile keyword you risk stale or invalid values.
One common example for using
volatileis for a flag to terminate a thread. If you’ve started a thread, and you want to be able to safely interrupt it from a different thread, you can have the thread periodically check a flag (i.e., to stop it, set the flag totrue). By making the flag volatile, you can ensure that the thread that is checking its value will see that it has been set totruewithout even having to use a synchronized block. -
Can we use volatile to be sure that there won’t be an issue with concurrency?
As CPUs can carry many instructions per second, fetching from RAM isn’t ideal for them. To improve this situation, processors use tricks like Out of Order Execution, Branch Prediction, Speculative Execution, and Caching.

As different cores execute more instructions and manipulate more data, they fill their caches with more relevant data and instructions. This will improve the overall performance at the expense of introducing cache coherence challenges.
We should think twice about what happens when one thread updates a cached value.
The thread cache and main memory values might differ. Therefore, even if one thread updates the values in the main memory, these changes are not instantly visible to other threads. This is called a visibility problem.
The volatile keyword helps us to resolve this issue by bypassing caching in a local thread. Thus, volatile variables are visible to all the threads, and all these threads will see the same value. Hence, when one thread updates the value, all the threads will see the new value
Although volatile keyword helps us with visibility, we still have another problem. In our increment example, we perform two operations with the variable count. First, we read this variable and then assign a new value to it. This means that the increment operation isn’t atomic.
What we’re facing here is a race condition. Each thread should read the value first, increment it, and then write it back. The problem will happen when several threads start working with the value, and read it before another one writes it.
This way, one thread may override the result written by another thread. The synchronized keyword can resolve this problem. However, this approach might create a bottleneck, and it’s not the most elegant solution to this problem.
Atomic values provide a better and more intuitive way to handle this issue. Their interface allows us to interact with and update values without a synchronization problem.
Internally, atomic classes ensure that, in this case, the increment will be an atomic operation. Thus, we can use it to create a thread-safe implementation:
-
Which Classes from concurrency package you know?
- Executor is an interface that represents an object that executes provided tasks.
- ExecutorService is a complete solution for asynchronous processing. It manages an in-memory queue and schedules submitted tasks based on thread availability.
- ScheduledExecutorService is a similar interface to ExecutorService, but it can perform tasks periodically. It can also schedule the task after some given fixed delay
- Future is used to represent the result of an asynchronous operation. It comes with methods for checking if the asynchronous operation is completed or not, getting the computed result, etc. What’s more, the cancel(boolean mayInterruptIfRunning) API cancels the operation and releases the executing thread. If the value of mayInterruptIfRunning is true, the thread executing the task will be terminated instantly.
- ThreadFactory acts as a thread (non-existing) pool which creates a new thread on demand. It eliminates the need of a lot of boilerplate coding for implementing efficient thread creation mechanisms.
- Synchronizers
- CountDownLatch is a utility class which blocks a set of threads until some operation completes. is initialized with a counter(Integer type); this counter decrements as the dependent threads complete execution. But once the counter reaches zero, other threads get released.
- CyclicBarrier works almost the same as CountDownLatch except that we can reuse it. Unlike CountDownLatch, it allows multiple threads to wait for each other using await() method(known as barrier condition) before invoking the final task.
- Semaphore is used for blocking thread level access to some part of the physical or logical resource. A semaphore contains a set of permits; whenever a thread tries to enter the critical section, it needs to check the semaphore if a permit is available or not. If a permit is not available (via tryAcquire()), the thread is not allowed to jump into the critical section; however, if the permit is available the access is granted, and the permit counter decreases.
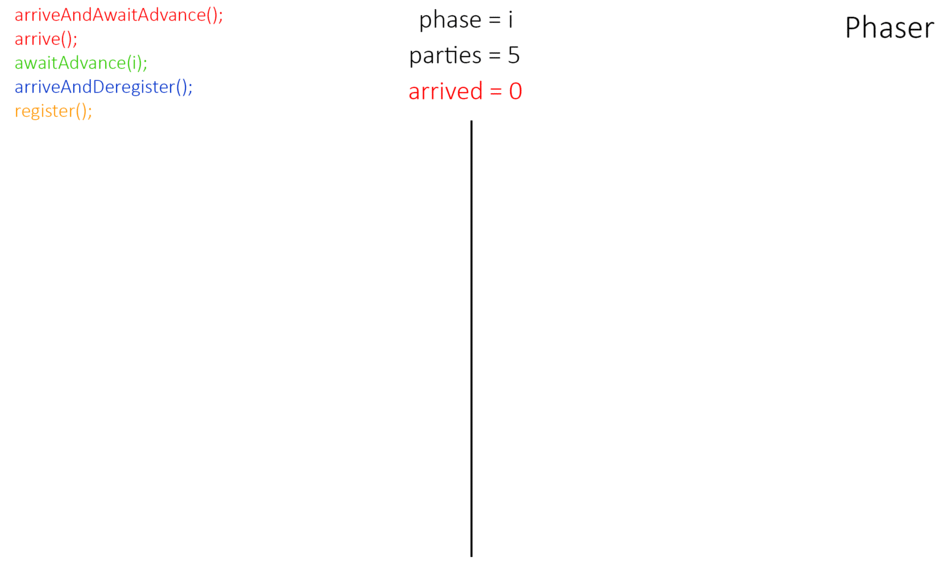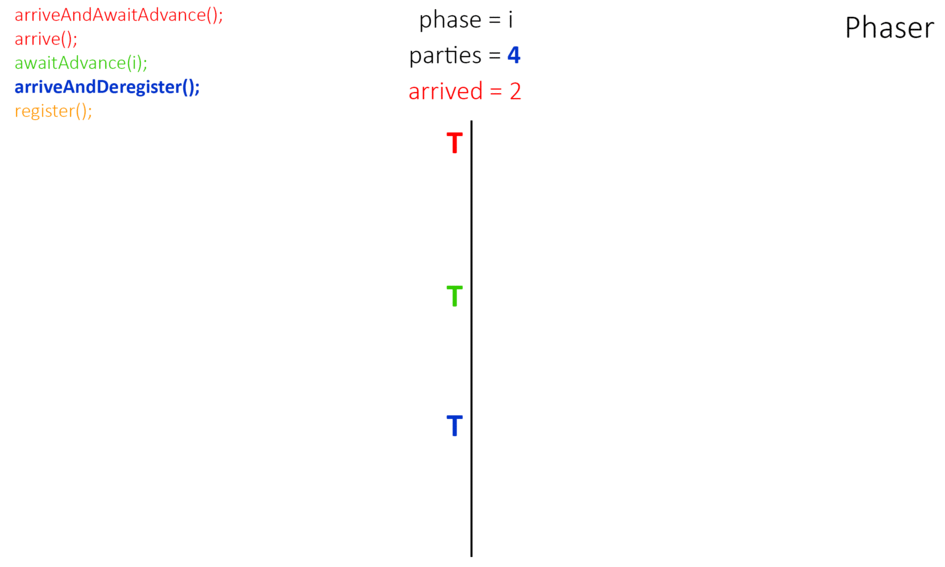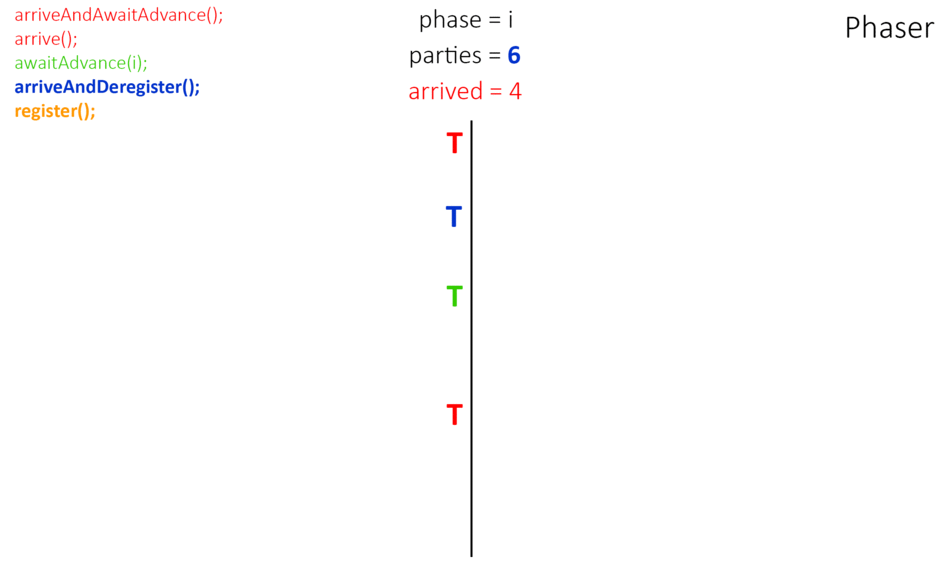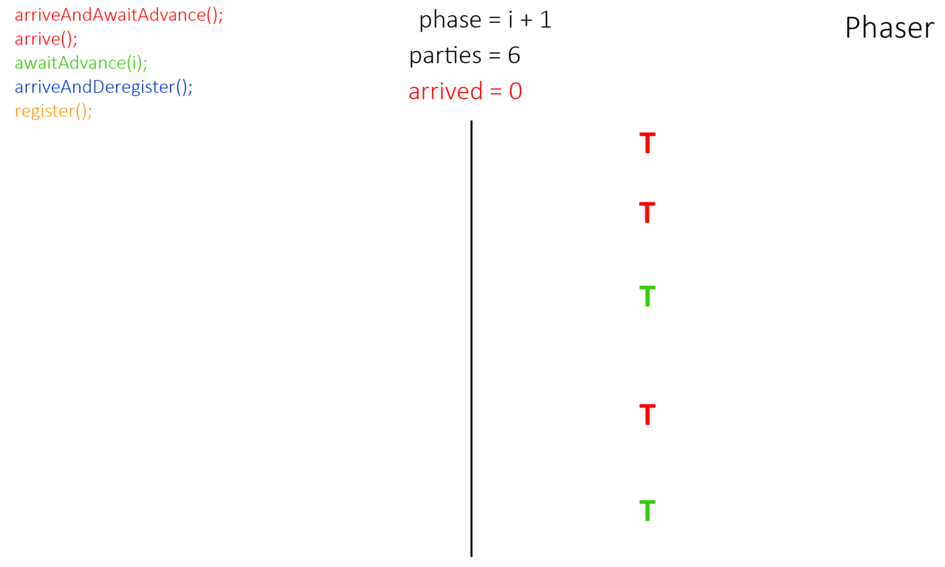
- Phaser is a more flexible solution than CyclicBarrier and CountDownLatch – used to act as a reusable barrier on which the dynamic number of threads need to wait before continuing execution
- Queues
- BlockingQueue - In asynchronous programming, one of the most common integration patterns is the producer-consumer pattern. The java.util.concurrent package comes with a data-structure know as BlockingQueue – which can be very useful in these async scenarios.
- DelayQueue - is an infinite-size blocking queue of elements where an element can only be pulled if it’s expiration time (known as user defined delay) is completed. Hence, the topmost element (head) will have the most amount delay and it will be polled last.
- Locks is a utility for blocking other threads from accessing a certain segment of code, apart from the thread that’s executing it currently.
- Executor is an interface that represents an object that executes provided tasks.
-
Difference between Mutex, Lock and Semaphore
Lock позволяет одному потоку войти в залоченный ресурс и не шарится с другими процессами.
Mutex – то же, что lock, но может быть system-wide, то есть может шариться с другими процессами. Реализован в операционной системе. Используется для resource sharing.
Semaphore – используется для signaling от одной задачи к другой (а НЕ ДЛЯ защиты нескольких эквивалентных ресурсов, как некоторые ошибочно полагают).
-
Is it possible to make array volatile in Java?
Yes, it is possible to make an array volatile in Java, but only the reference which is pointing to an array, not the whole array. Therefore, if one thread changes the reference variable points to another array, which will provide a volatile guarantee.
-
How would you call wait() method? Would you use if block or loop, and why?
wait() method should always be called in loop. It is likely that, until the thread gets CPU to start running again, the condition may not hold. Therefore, it is always advised to check the condition in loop before continuing.
Executors
-
What Are Executor and Executorservice? What Are the Differences Between These Interfaces?
Executor and ExecutorService are two related interfaces of java.util.concurrent framework. Executor is a very simple interface with a single execute method accepting Runnable instances for execution. In most cases, this is the interface that your task-executing code should depend on.
ExecutorService extends the Executor interface with multiple methods for handling and checking the lifecycle of a concurrent task execution service (termination of tasks in case of shutdown) and methods for more complex asynchronous task handling including Futures.
-
What Are the Available Implementations of Executorservice in the Standard Library?
- ThreadPoolExecutor — for executing tasks using a pool of threads. Once a thread is finished executing the task, it goes back into the pool. If all threads in the pool are busy, then the task has to wait for its turn.
- ScheduledThreadPoolExecutor allows to schedule task execution instead of running it immediately when a thread is available. It can also schedule tasks with fixed rate or fixed delay.
- ForkJoinPool is a special ExecutorService for dealing with recursive algorithms tasks. If you use a regular ThreadPoolExecutor for a recursive algorithm, you will quickly find all your threads are busy waiting for the lower levels of recursion to finish. The ForkJoinPool implements the so-called work-stealing algorithm that allows it to use available threads more efficiently.
-
What is ThreadPool?
ThreadPool - allows you to create a queue of threads, which can save resources on context switching
- newFixedThreadPool - pool of multiple threads
- newSingleThreadExecutor - pool from one thread
How to use
- Don’t queue tasks that concurrently wait for results from other tasks.
- Be careful while using threads for a long lived operation. It might result in the thread waiting forever and would eventually lead to resource leakage.
- The Thread Pool has to be ended explicitly at the end. If this is not done, then the program goes on executing and never ends. Call shutdown() on the pool to end the executor. If you try to send another task to the executor after shutdown, it will throw a RejectedExecutionException.
- One needs to understand the tasks to effectively tune the thread pool. If the tasks are very contrasting then it makes sense to use different thread pools for different types of tasks so as to tune them properly.
- You can restrict maximum number of threads that can run in JVM, reducing chances of JVM running out of memory.
- If you need to implement your loop to create new threads for processing, using ThreadPool will help to process faster, as ThreadPool does not create new Threads after it reached it’s max limit.
- After completion of Thread Processing, ThreadPool can use the same Thread to do another process(so saving the time and resources to create another Thread.)
-
Risks in using Thread Pool?
- While deadlock can occur in any multi-threaded program, thread pools introduce another case of deadlock, one in which all the executing threads are waiting for the results from the blocked threads waiting in the queue due to the unavailability of threads for execution.
- Thread Leakage occurs if a thread is removed from the pool to execute a task but not returned to it when the task completed. As an example, if the thread throws an exception and pool class does not catch this exception, then the thread will simply exit, reducing the size of the thread pool by one. If this repeats many times, then the pool would eventually become empty and no threads would be available to execute other requests.
- Resource Thrashing :If the thread pool size is very large then time is wasted in context switching between threads. Having more threads than the optimal number may cause starvation problem leading to resource thrashing as explained.
-
What is ThreadPoolExecutor?
ThreadPoolExecutor is an extensible thread pool implementation with lots of parameters and hooks for fine-tuning. It uses BlockingQueue for new tasks and HashSet for workers, that pull new tasks from queue, while running their’s run method.
The corePoolSize parameter is the number of core threads that will be instantiated and kept in the pool. When a new task comes in, if all core threads are busy and the internal queue is full, the pool is allowed to grow up to maximumPoolSize.
The keepAliveTime parameter is the interval of time for which the excessive threads (instantiated in excess of the corePoolSize) are allowed to exist in the idle state. By default, the ThreadPoolExecutor only considers non-core threads for removal.
-
Types of ThreadPools
newFixedThreadPool
newFixedThreadPool method creates a ThreadPoolExecutor with equal corePoolSize and maximumPoolSize parameter values and a zero keepAliveTime. This means that the number of threads in this thread pool is always the same
newCachedThreadPool
newCachedThreadPool() method. This method does not receive a number of threads at all. We set the corePoolSize to 0 and set the maximumPoolSize to Integer.MAX_VALUE. Finally, the keepAliveTime is 60 seconds:
A typical use case is when we have a lot of short-living tasks in our application.
newSingleThreadExecutor
newSingleThreadExecutor() API creates another typical form of ThreadPoolExecutor containing a single thread. The single thread executor is ideal for creating an event loop. The corePoolSize and maximumPoolSize parameters are equal to 1, and the keepAliveTime is 0.
scheduledThreadPoolExecutor
- schedule method allows us to run a task once after a specified delay.
- scheduleAtFixedRate method allows us to run a task after a specified initial delay and then run it repeatedly with a certain period.
- scheduleWithFixedDelay method is similar to scheduleAtFixedRate in that it repeatedly runs the given task, but the specified delay is measured between the end of the previous task and the start of the next.
-
Describe the Purpose and Use-Cases of the Fork/Join Framework.
The fork/join framework allows parallelizing recursive algorithms. The main problem with parallelizing recursion using something like ThreadPoolExecutor is that you may quickly run out of threads because each recursive step would require its own thread, while the threads up the stack would be idle and waiting.
The fork/join framework entry point is the ForkJoinPool class which is an implementation of ExecutorService. It implements the work-stealing algorithm, where idle threads try to “steal” work from busy threads. This allows to spread the calculations between different threads and make progress while using fewer threads than it would require with a usual thread pool.
Worker threads can execute only one task at a time, but the ForkJoinPool doesn’t create a separate thread for every single subtask. Instead, each thread in the pool has its own double-ended queue (or deque, pronounced “deck”) that stores tasks.
Simply put, free threads try to “steal” work from deques of busy threads.
By default, a worker thread gets tasks from the head of its own deque. When it is empty, the thread takes a task from the tail of the deque of another busy thread or from the global entry queue since this is where the biggest pieces of work are likely to be located.
-
What is ForkJoinPool
ForkJoinPool is the central part of the fork/join framework introduced in Java 7. It solves a common problem of spawning multiple tasks in recursive algorithms. We'll run out of threads quickly by using a simple ThreadPoolExecutor, as every task or subtask requires its own thread to run.
In a fork/join framework, any task can spawn (fork) a number of subtasks and wait for their completion using the join method. The benefit of the fork/join framework is that it does not create a new thread for each task or subtask, instead implementing the work-stealing algorithm. The work-stealing algorithm optimizes resource utilization by allowing idle threads to steal tasks from busy ones.
Synchronization
-
What Is the Meaning of a Synchronized Keyword in the Definition of a Method? of a Static Method? Before a Block?
- The synchronized keyword before a block means that any thread entering this block has to acquire the monitor (the object in brackets). If the monitor is already acquired by another thread, the former thread will enter the BLOCKED state and wait until the monitor is released.
- A synchronized instance method has the same semantics, but the instance itself acts as a monitor.
- For a static synchronized method, the monitor is the Class object representing the declaring class.
-
If Two Threads Call a Synchronized Method on Different Object Instances Simultaneously, Could One of These Threads Block? What If the Method Is Static?
If the method is an instance method, then the instance acts as a monitor for the method. Two threads calling the method on different instances acquire different monitors, so none of them gets blocked.
If the method is static, then the monitor is the Class object. For both threads, the monitor is the same, so one of them will probably block and wait for another to exit the synchronized method.
-
What Is the Purpose of the Wait, Notify and Notifyall Methods of the Object Class?
A thread that owns the object’s monitor (for instance, a thread that has entered a synchronized section guarded by the object) may call object.wait() to temporarily release the monitor and give other threads a chance to acquire the monitor. This may be done, for instance, to wait for a certain condition.
When another thread that acquired the monitor fulfills the condition, it may call object.notify() or object.notifyAll() and release the monitor. The notify method awakes a single thread in the waiting state, and the notifyAll method awakes all threads that wait for this monitor, and they all compete for re-acquiring the lock.
-
What is Semaphore?
Semaphore - ограничивает количество одновременно выполняемых потоков

-
What is CountDownLatch?
CountDownLatch - предоставляет возможность любому количеству потоков в блоке кода ожидать до тех пор, пока не завершится определенное количество операций, выполняющихся в других потоках, перед тем как они будут «отпущены»
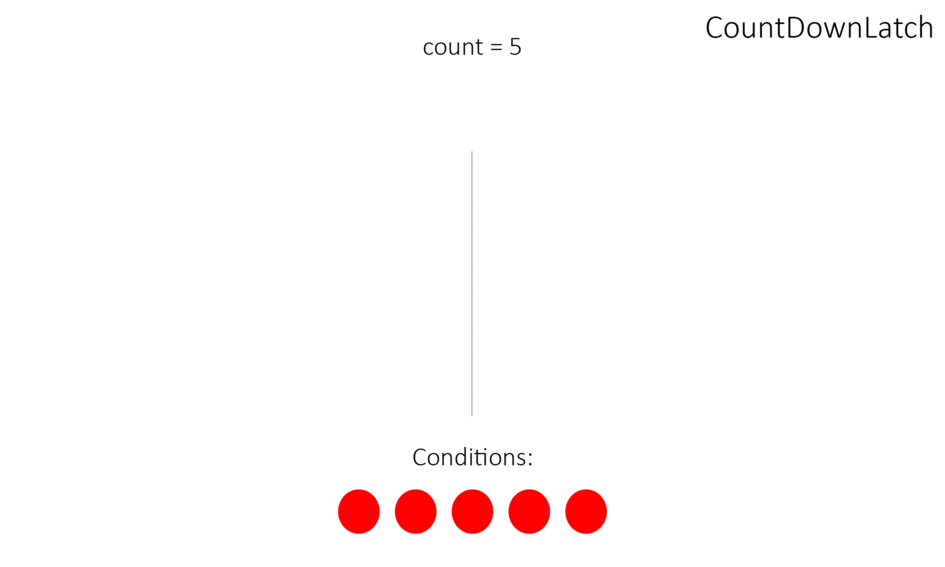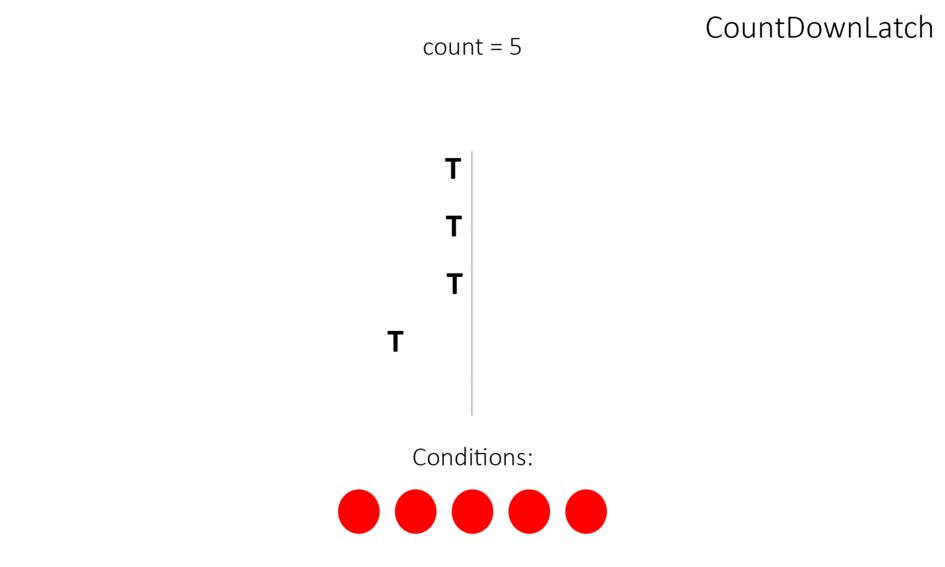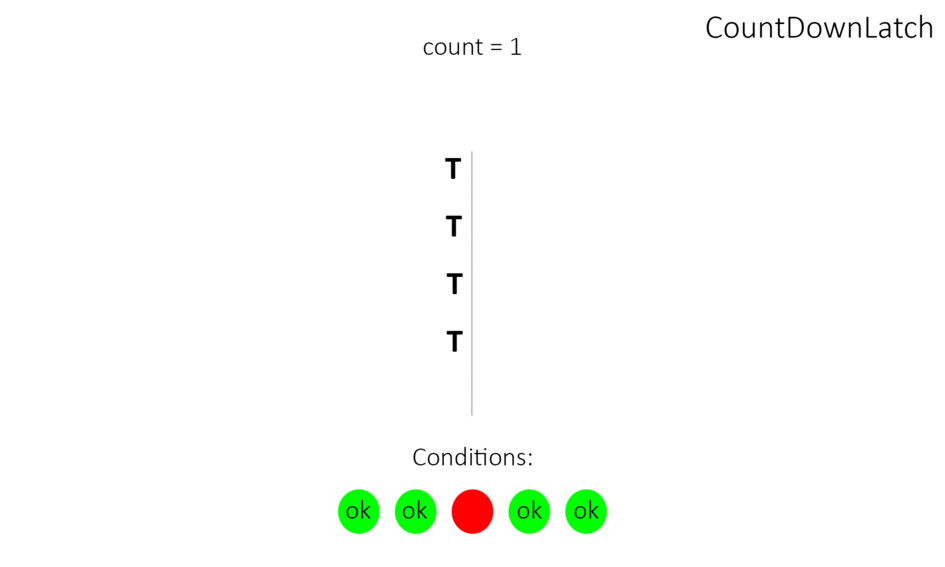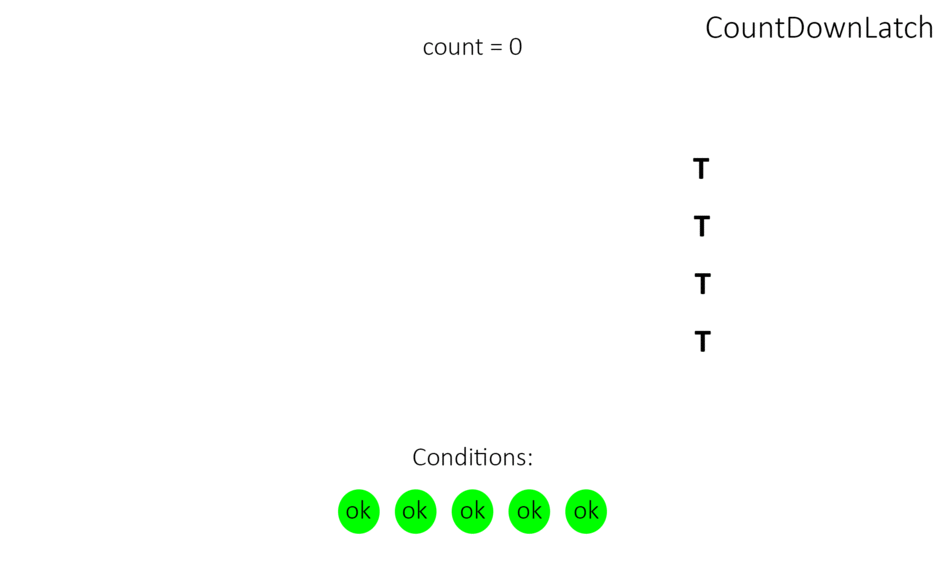
-
What is CycleBarrier?
CycleBarrier - как только нужное количество потоков достигло нужной точки, все потоки продолжают работу
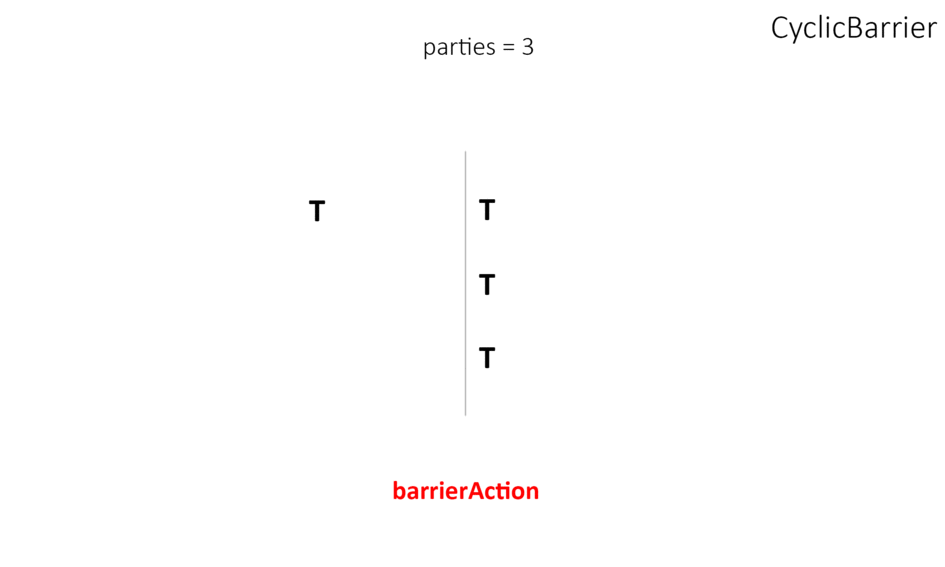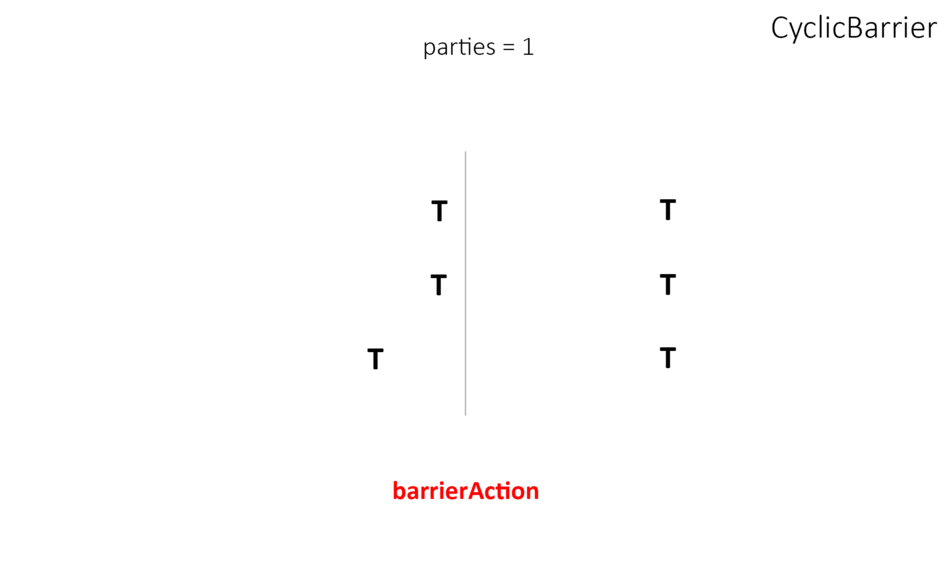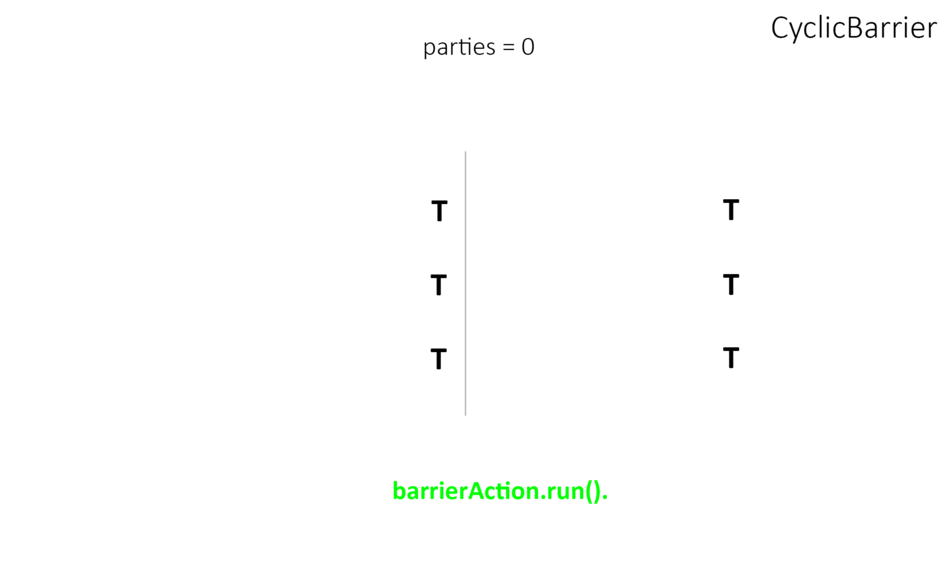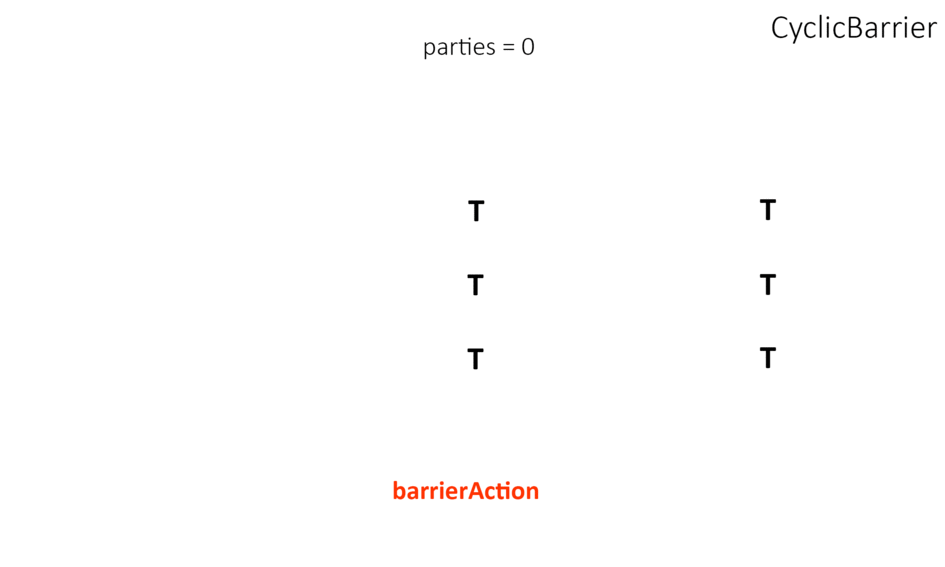
-
What is Exchanger?
Exchanger - поток, вызывающий у обменника метод exchange() блокируется и ждет другой поток. Когда другой поток вызовет тот же метод, произойдет обмен объектами: каждая из них получит аргумент другой в методе exchange()
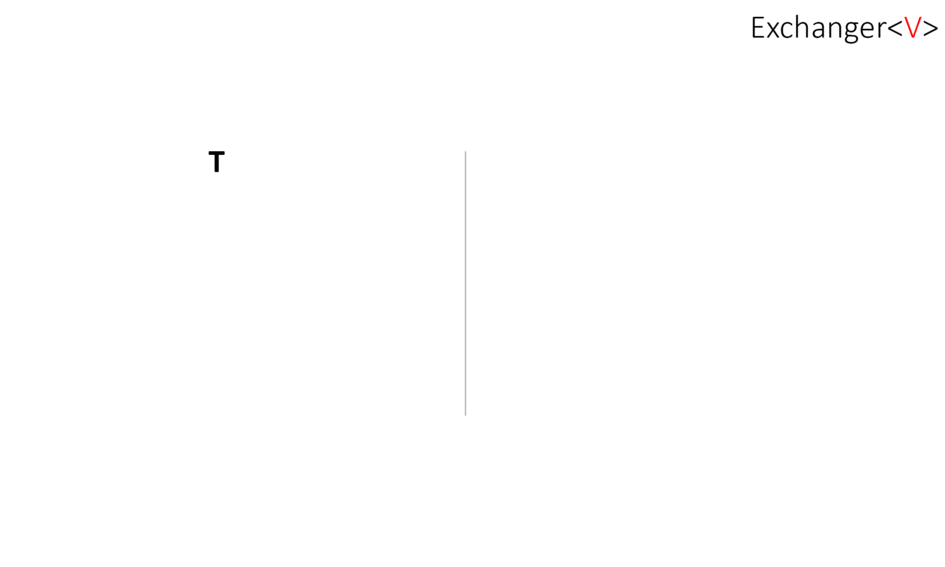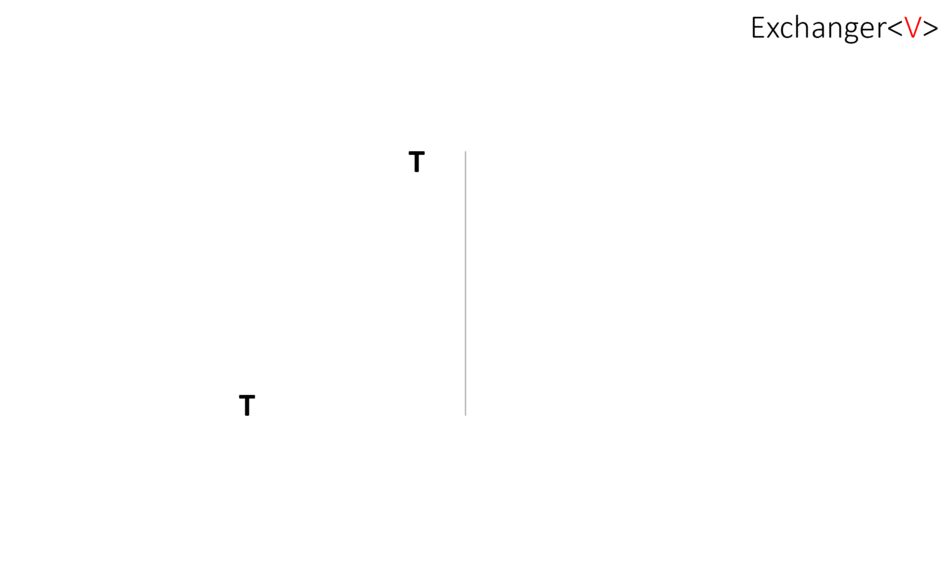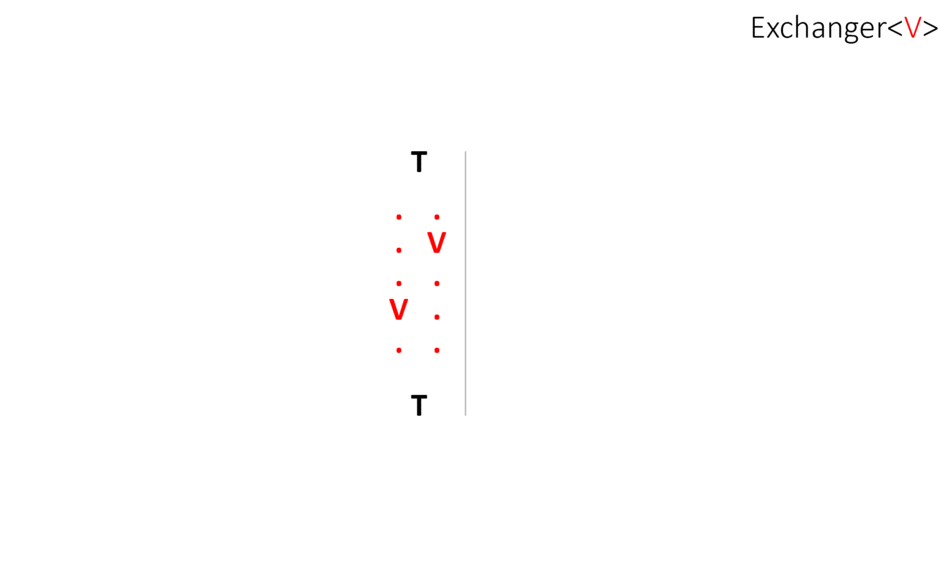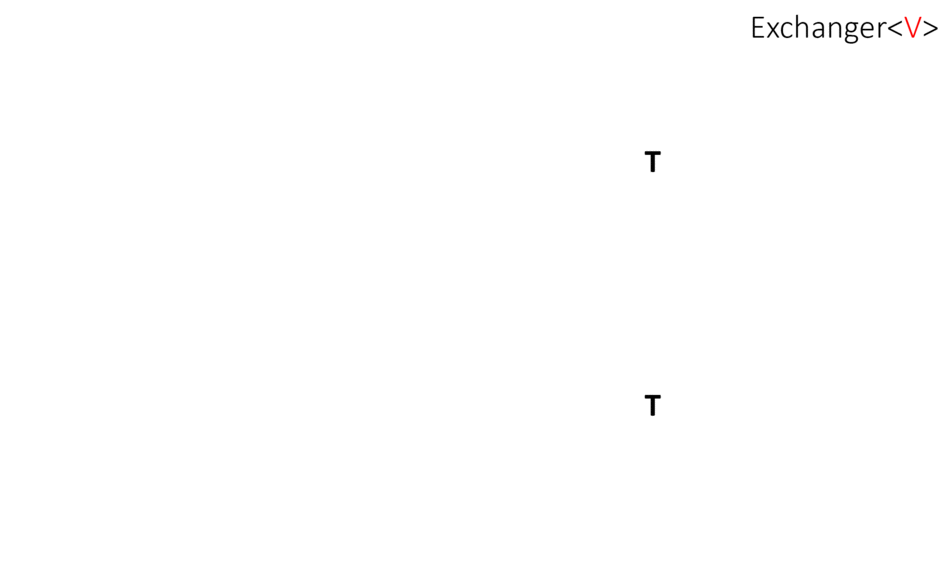
-
What is What is Phaser?
Phaser - то же, что и CyclicBarrier, но позволяет синхронизировать потоки, представляющие отдельную фазу или стадию выполнения общего действия.
Atomic
-
Which Operations Are Atomic?
- A write to an int (32-bit) variable is guaranteed to be atomic, whether it is volatile or not.
- A long (64-bit) variable could be written in two separate steps, for example, on 32-bit architectures, so by default, there is no atomicity guarantee. However, if you specify the volatile modifier, a long variable is guaranteed to be accessed atomically.
- The increment operation is usually done in multiple steps (retrieving a value, changing it and writing back), so it is never guaranteed to be atomic, wether the variable is volatile or not. If you need to implement atomic increment of a value, you should use classes AtomicInteger, AtomicLong etc.
-
What are atomic variables
Потокобезопасные переменные, которые поддержиивают атомарные операции. Атомарность поддерживается с помощью Compare and Swap. То есть при установку значения происходит проверка, соответствует ли новое значение ожидаемому. Если оно не соответствует, то операция не выполнена и она повторяется снова.
Collections
-
Blocking Queue Synchronization
The following BlockingQueue implementation shows how multiple threads work together via the wait-notify pattern. If we put an element into an empty queue, all threads that were waiting in the take method wake up and try to receive the value. If we put an element into a full queue, the put method _wait_s for the call to the get method. The get method removes an element and notifies the threads waiting in the put method that the queue has an empty place for a new item.
public class BlockingQueue<T> { private List<T> queue = new LinkedList<T>(); private int limit = 10; public synchronized void put(T item) { while (queue.size() == limit) { try { wait(); } catch (InterruptedException e) {} } if (queue.isEmpty()) { notifyAll(); } queue.add(item); } public synchronized T take() throws InterruptedException { while (queue.isEmpty()) { try { wait(); } catch (InterruptedException e) {} } if (queue.size() == limit) { notifyAll(); } return queue.remove(0); } } -
Blocking queue
Java BlockingQueue implementations are thread-safe. All queuing methods are atomic in nature and use internal locks or other forms of concurrency control.
Java BlockingQueue interface is part of java collections framework and it’s primarily used for implementing producer consumer problem. We don’t need to worry about waiting for the space to be available for producer or object to be available for consumer in BlockingQueue because it’s handled by implementation classes of BlockingQueue.
-
Collections.synchronizedCollection()
Возвращает потокобезопасную коллекцию, на основе переданной. Достигает потокобезопасности через блокировку монитора.
-
Concurrent collections
Отдельные коллекции, например ConcurrentHashMap. Достигают синхронизации с помощью деления коллекции на сегменты. То есть несколько потоков могут обратиться к map одновременно, но только к разным ее блокам.
-
CopyOnWrite
CopyOnWrite коллекции удобно использовать, когда write операции довольно редки, например при реализации механизма подписки listeners и прохода по ним. Все операции по изменению коллекции (add, set, remove) приводят к созданию новой копии внутреннего массива. Тем самым гарантируется, что при проходе итератором по коллекции не кинется ConcurrentModificationException. Следует помнить, что при копировании массива копируются только референсы (ссылки) на объекты (shallow copy), т.ч. доступ к полям элементов не thread-safe.
Locks
-
Assume a thread has a lock on it, calling the sleep() method on that thread will release the lock?
A thread that has a lock won't be released even after it calls sleep(). Despite the thread sleeping for a specified period of time, the lock will not be released.
-
What is Lock library
Lock is a more flexible and sophisticated thread synchronization mechanism than the standard synchronized block.
Представляет собой альтернативные и более гибкие механизмы синхронизации потоков по сравнению с базовыми synchronized, wait, notify, notifyAll. Using synchronized:
- It is not possible to interrupt a thread waiting to acquire a lock (lock Interruptibly).
- It is not possible to attempt to acquire a lock without being willing to wait for it forever (try lock).
- Cannot implement non-block-structured locking disciplines, as intrinsic locks must be released in the same block in which they are acquired.
- Faireless locking
-
ReentrantLock
ReentrantLock class implements the Lock interface. It offers the same concurrency and memory semantics, as the implicit monitor lock accessed using synchronized methods and statements, with extended capabilities.
We need to make sure that we are wrapping the lock() and the unlock() calls in the try-finally block to avoid the deadlock situations.
Let's see how the tryLock() works:
public void performTryLock(){ //... boolean isLockAcquired = lock.tryLock(1, TimeUnit.SECONDS); if(isLockAcquired) { try { //Critical section here } finally { lock.unlock(); } } //... }In this case, the thread calling tryLock(), will wait for one second and will give up waiting if the lock isn't available.
-
ReadWriteLock
- поддерживает пару связанных блокировок: одну для операций только для чтения, а другую - для записи. Блокировка чтения может удерживаться одновременно несколькими потоками чтения, пока нет писателей. Блокировка записи является исключительной.
-
ReentrantReadWriteLock
ReentrantReadWriteLock
ReentrantReadWriteLock class implements the ReadWriteLock interface.
Let's see rules for acquiring the ReadLock or WriteLock by a thread:
Read Lock – if no thread acquired the write lock or requested for it then multiple threads can acquire the read lock
Write Lock – if no threads are reading or writing then only one thread can acquire the write lock
Map<String,String> syncHashMap = new HashMap<>(); ReadWriteLock lock = new ReentrantReadWriteLock(); // ... Lock writeLock = lock.writeLock(); public void put(String key, String value) { try { writeLock.lock(); syncHashMap.put(key, value); } finally { writeLock.unlock(); } } public String remove(String key){ try { writeLock.lock(); return syncHashMap.remove(key); } finally { writeLock.unlock(); } } -
StampedLock
StampedLock
StampedLock is introduced in Java 8. It also supports both read and write locks. However, lock acquisition methods return a stamp that is used to release a lock or to check if the lock is still valid:
Map<String,String> map = new HashMap<>(); private StampedLock lock = new StampedLock(); public void put(String key, String value){ long stamp = lock.writeLock(); try { map.put(key, value); } finally { lock.unlockWrite(stamp); } } public String get(String key) throws InterruptedException { long stamp = lock.readLock(); try { return map.get(key); } finally { lock.unlockRead(stamp); } }Another feature provided by StampedLock is optimistic locking. Most of the time read operations don't need to wait for write operation completion and as a result of this, the full-fledged read lock isn't required.
Instead, we can upgrade to read lock:
public String readWithOptimisticLock(String key) { long stamp = lock.tryOptimisticRead(); String value = map.get(key); if(!lock.validate(stamp)) { stamp = lock.readLock(); try { return map.get(key); } finally { lock.unlock(stamp); } } return value; } -
Condition
Condition
The Condition class provides the ability for a thread to wait for some condition to occur while executing the critical section.
This can occur when a thread acquires the access to the critical section but doesn't have the necessary condition to perform its operation. For example, a reader thread can get access to the lock of a shared queue, which still doesn't have any data to consume.
Traditionally Java provides wait(), notify() and notifyAll() methods for thread intercommunication. Conditions have similar mechanisms, but in addition, we can specify multiple conditions:
Stack<String> stack = new Stack<>(); int CAPACITY = 5; ReentrantLock lock = new ReentrantLock(); Condition stackEmptyCondition = lock.newCondition(); Condition stackFullCondition = lock.newCondition(); public void pushToStack(String item){ try { lock.lock(); while(stack.size() == CAPACITY) { stackFullCondition.await(); } stack.push(item); stackEmptyCondition.signalAll(); } finally { lock.unlock(); } } public String popFromStack() { try { lock.lock(); while(stack.size() == 0) { stackEmptyCondition.await(); } return stack.pop(); } finally { stackFullCondition.signalAll(); lock.unlock(); } } -
Lock vs Synchronized Block
There are few differences between the use of synchronized block and using Lock API's:
- A synchronized block is fully contained within a method – we can have Lock API's lock() and unlock() operation in separate methods
- A synchronized block doesn't support the fairness, any thread can acquire the lock once released, no preference can be specified. We can achieve fairness within the Lock APIs by specifying the fairness property. It makes sure that longest waiting thread is given access to the lock
- A thread gets blocked if it can't get an access to the synchronized block. The Lock API provides tryLock() method. The thread acquires lock only if it's available and not held by any other thread. This reduces blocking time of thread waiting for the lock
- A thread which is in “waiting” state to acquire the access to synchronized block, can't be interrupted. The Lock API provides a method lockInterruptibly() which can be used to interrupt the thread when it's waiting for the lock
-
Issues
Deadlock
Состояние, когда два потока заняли ресурсы, к которым хочет обратиться противоположный поток.
Deadlock Prevention
- Lock Ordering - If you make sure that all locks are always taken in the same order by any thread, deadlocks cannot occur.
- Lock Timeout - put a timeout on lock attempts meaning a thread trying to obtain a lock will only try for so long before giving up. If a thread does not succeed in taking all necessary locks within the given timeout, it will backup, free all locks taken, wait for a random amount of time and then retry.
- Interruptible lock acquisition allows locking to be used within cancellable activities.The lockInterruptibly method allows us to try and acquire a lock while being available for interruption.
Анализ объектов в дедлоке
JJVM allows you to diagnose deadlocks by displaying them in thread dumps. Such dumps include information on the state of the flow. If it is locked, the dump contains information about the monitor the stream is waiting to release. JVM looks at a graph of expected (busy) monitors before output of the dump threads, and if it finds a loop, it adds information about mutual locking, specifying the monitors and threads involved.





JMM
-
What Is Java Memory Model (Jmm)?
Java Memory Model is a part of Java language specification described in Chapter 17.4. It specifies how multiple threads access common memory in a concurrent Java application, and how data changes by one thread are made visible to other threads.
The need for memory model arises from the fact that the way your Java code is accessing data is not how it actually happens on the lower levels. Memory writes and reads may be reordered or optimized by the Java compiler, JIT compiler, and even CPU, as long as the observable result of these reads and writes is the same.
This can lead to counter-intuitive results when your application is scaled to multiple threads because most of these optimizations take into account a single thread of execution (the cross-thread optimizers are still extremely hard to implement). Another huge problem is that the memory in modern systems is multilayered: multiple cores of a processor may keep some non-flushed data in their caches or read/write buffers, which also affects the state of the memory observed from other cores.
-
Basic Ideas of JMM
- Actions, these are inter-thread actions that can be executed by one thread and detected by another thread, like reading or writing variables, locking/unlocking monitors and so on
- Synchronization actions, a certain subset of actions, like reading/writing a volatile variable, or locking/unlocking a monitor
- Program Order (PO), the observable total order of actions inside a single thread
- Synchronization Order (SO), the total order between all synchronization actions — it has to be consistent with Program Order, that is, if two synchronization actions come one before another in PO, they occur in the same order in SO
- synchronizes-with (SW) relation between certain synchronization actions, like unlocking of monitor and locking of the same monitor (in another or the same thread)
- Happens-before Order — combines PO with SW (this is called transitive closure in set theory) to create a partial ordering of all actions between threads. If one action happens-before another, then the results of the first action are observable by the second action (for instance, write of a variable in one thread and read in another)
- Happens-before consistency — a set of actions is HB-consistent if every read observes either the last write to that location in the happens-before order, or some other write via data race
- Execution — a certain set of ordered actions and consistency rules between them
-
What is Visibility in JMM?
One thread may not see the changes made by another because the variables are saved to the registers and the local CPU cache
-
What is Reordering in JMM?
Compiler can move operations to improve performance
-
What Is a Volatile Field and What Guarantees Does the Jmm Hold for Such Field?
A volatile field has special properties according to the Java Memory Model (see Q9). The reads and writes of a volatile variable are synchronization actions, meaning that they have a total ordering (all threads will observe a consistent order of these actions). A read of a volatile variable is guaranteed to observe the last write to this variable, according to this order.
If you have a field that is accessed from multiple threads, with at least one thread writing to it, then you should consider making it volatile, or else there is a little guarantee to what a certain thread would read from this field.
Another guarantee for volatile is atomicity of writing and reading 64-bit values (long and double). Without a volatile modifier, a read of such field could observe a value partly written by another thread.
-
What Special Guarantees Does the JMM Hold for Final Fields of a Class?
JVM basically guarantees that final fields of a class will be initialized before any thread gets hold of the object. Without this guarantee, a reference to an object may be published, i.e. become visible, to another thread before all the fields of this object are initialized, due to reorderings or other optimizations. This could cause racy access to these fields.
This is why, when creating an immutable object, you should always make all its fields final, even if they are not accessible via getter methods.
-
What Happens Before stands for?
Happens before - Let there be thread X and thread Y (not necessarily different from thread X). And let there be operations A (running in X thread) and B (running in Y thread).
In this case, A happens-before B means that all changes made by a thread X before the moment of operation A and the changes that this operation caused are visible to the thread Y at the moment of execution of operation B and after execution of that operation.
Happens-before is a concept, a phenomenon, or simply a set of rules that define the basis for reordering of instructions by a compiler or CPU.
- Within a single thread, any operation happens-before any operation following it in source code
- Release lock (unlock) happens-before capture the same lock (lock)
- Output from synchronized block/method happens-before input to synchronized block/method on same monitor
- Write volatile field happens-before reading the same volatile field
- Завершение метода run экземпляра класса Thread happens-before выход из метода join() или возвращение false методом isAlive() экземпляром того же треда
- Вызов метода start() экземпляра класса Thread happens-before начало метода run() экземпляра того же треда
- Завершение конструктора happens-before начало метода finalize() этого класса
- Вызов метода interrupt() на потоке happens-before когда поток обнаружил, что данный метод был вызван либо путем выбрасывания исключения InterruptedException, либо с помощью методов isInterrupted() или interrupted()
- An unlock on a monitor happens-before every subsequent lock on that monitor.
- A write to a volatile field happens-before every subsequent read of that field.
- A call to start() on a thread happens-before any actions in the started thread.
- All actions in a thread happen-before any other thread successfully return from a join() on that thread.
- The default initialization of any object happens-before any other actions (other than default-writes) of a program.
- When a statement invokes Thread.start, every statement that has a happens-before relationship with that statement also has a happens-before relationship with every statement executed by the new thread. The effects of the code that led up to the creation of the new thread are visible to the new thread.
- When a thread terminates and causes a Thread.join in another thread to return, then all the statements executed by the terminated thread have a happens-before relationship with all the statements following the successful join. The effects of the code in the thread are now visible to the thread that performed the join.
Issues
-
Describe the Conditions of Deadlock, Livelock, and Starvation. Describe the Possible Causes of These Conditions.
Deadlock is a condition within a group of threads that cannot make progress because every thread in the group has to acquire some resource that is already acquired by another thread in the group. The most simple case is when two threads need to lock both of two resources to progress, the first resource is already locked by one thread, and the second by another. These threads will never acquire a lock to both resources and thus will never progress.
Livelock is a case of multiple threads reacting to conditions, or events, generated by themselves. An event occurs in one thread and has to be processed by another thread. During this processing, a new event occurs which has to be processed in the first thread, and so on. Such threads are alive and not blocked, but still, do not make any progress because they overwhelm each other with useless work.
Starvation is a case of a thread unable to acquire resource because other thread (or threads) occupy it for too long or have higher priority. A thread cannot make progress and thus is unable to fulfill useful work.
-
What is a Race Condition?
Race condition is a condition of a program where its behavior depends on relative timing or interleaving of multiple threads or processes
If we are changing the same walue in two threads at the same moment, we can get incorrect result
Thread 1 Thread 2 Read var “A” = 10 Read var “A” = 10 Increment “A” Decrement “A” Write var “A” = 11 Write var “A” = 9 As a result we have var “A” = 9 instead of 10. Real world example - bank transactions for the same account
-
How to prevent DeadLock
- Lock Ordering - If you make sure that all locks are always taken in the same order by any thread, deadlocks cannot occur.
- Lock Timeout - put a timeout on lock attempts meaning a thread trying to obtain a lock will only try for so long before giving up. If a thread does not succeed in taking all necessary locks within the given timeout, it will backup, free all locks taken, wait for a random amount of time and then retry.
- Interruptible lock acquisition allows locking to be used within cancellable activities.The lockInterruptibly method allows us to try and acquire a lock while being available for interruption.
-
How to analyse objects in deadlock
JVM allows you to diagnose deadlocks by displaying them in thread dumps. Such dumps include information on the state of the flow. If it is locked, the dump contains information about the monitor the stream is waiting to release. JVM looks at a graph of expected (busy) monitors before output of the dump threads, and if it finds a loop, it adds information about mutual locking, specifying the monitors and threads involved.
jstack - gives thread dump
Collections
**Collection**: An interface representing an unordered "bag" of items, called "elements". The "next" element is undefined (random).
-
Describe the Collections Type Hierarchy. What Are the Main Interfaces, and What Are the Differences Between Them?
he Iterable interface represents any collection that can be iterated using the for-each loop. The Collection interface inherits from Iterable and adds generic methods for checking if an element is in a collection, adding and removing elements from the collection, determining its size etc.
The List, Set, and Queue interfaces inherit from the Collection interface.
List is an ordered collection, and its elements can be accessed by their index in the list.
Set is an unordered collection with distinct elements, similar to the mathematical notion of a set.
Queue is a collection with additional methods for adding, removing and examining elements, useful for holding elements prior to processing.
Map interface is also a part of the collection framework, yet it does not extend Collection. This is by design, to stress the difference between collections and mappings which are hard to gather under a common abstraction. The Map interface represents a key-value data structure with unique keys and no more than one value for each key.
Build Tools
Maven
-
How to disable tests in maven?
mvn -DskipTest=true
-
What is Maven?
Фреймворк для автоматизации сборки проектов на основе описания их структуры в файлах на языке POM,
-
Dependencies types
В maven есть 2 типа зависимостей:
- Прямые - зависимости прописанные в pom.xml в теге
- Транзитивные зависимости - зависимости, которые наобходимы для зависимостей (A --> B --> C).
- Прямые - зависимости прописанные в pom.xml в теге
-
Pom types
Super POM
Основной файл, от которого наследуются все pom файлы(По аналогии с object в Java). Он задает дефолтные значения для конфигурации
Simplest POM
Самый простой пом, который можно создать. Он должен состоять из версии мавена, groupId, artifactId, версии проекта
Effective POM
Является сочетанием дефолтных настроек из super POM и конфигурации заданной для приложения. Можно получить через mvn help:effective-pom
-
Maven lifecycle
- Валидация - проверка корректности необходимой для сборки информации(в том числе загрузка зависимостей)
- Компиляция кода
- Компиляция тестов
- Прогон тестов
- упаковка кода
- Интеграционные тесты
- установка пакета в локальный репозиторий
- копирование в удаленный репозиторий
-
What is bom?
BOM stands for Bill Of Materials. A BOM is a special kind of POM that is used to control the versions of a project’s dependencies and provide a central place to define and update those versions.
BOM provides the flexibility to add a dependency to our module without worrying about the version that we should depend on.
-
Types of repositories
- Local - директория на на компьютере, создается при первом запуске maven
- Central - основной репозиторий, обеспечиваемый сообществом Maven
- Remote - кастомный удаленный репозиторий, который можно использовать, если нет зависимости в Central
-
Maven scopes
- test - нужен только в тестах
- compile только этап компиляции, включается в сборку, дефолтный
- provided - используется только на этапе компиляции, в сборку не включается
- runtime - не нужен для компиляции, будет использоваться только во время работы приложения
- system - как provided, но путь указывается явно
-
What is archetype
Шаблон вашего будущего проекта или, цитируя официальную документацию: «архетип есть модель по которой делаются все остальные вещи такого рода
-
What is Dependency hell
Антипаттерн управления зависимостями на проекте, при котором усложняется граф зависимостей библиотек и возникает ситуация, когда библиотеки требуют разные версии одной и той же зависимости. Или одна библиотека может косвенно потребовать несколько версий одной и той же зависимости.
The conflict here comes when 2 dependencies refer to different versions of a specific artifact. Which one will be included by Maven?
The answer here is the “nearest definition”. This means that the version used will be the closest one to our project in the tree of dependencies. This is called dependency mediation.
A -> B -> C -> D 1.4 and A -> E -> D 1.0This example shows that project A depends on B and E. B and E have their own dependencies which encounter different versions of the D artifact. Artifact D 1.0 will be used in the build of A project because the path through E is shorter.
-
How to Fix?
- Удаление дублирующихся зависимостей mvn dependency:analyze-duplicate
- Удаление неиспользуемых записанных зависимостей mvn dependency:analyze
- Добавление используемых не записанных зависимостей mvn dependency:analyze
- Нахождение нескольких версий одной библиотеки, поиск мест, где используются эти версии и обновление их до одной
- Дублирующиеся классы - в разных библиотеках есть классы со схожей реализацией tattletale-maven
-
What is DependencyManagement?
Simply put, Dependency Management is a mechanism to centralize the dependency information.
When we have a set of projects that inherit a common parent, we can put all dependency information in a shared POM file called BOM. BOM is a normal POM file with a dependencyManagement section where we can include all an artifact's information and versions.
-
What is the order of dependencies versions applying
- The version of the artifact's direct declaration in our project pom
- The version of the artifact in the parent project
- The version in the imported pom, taking into consideration the order of importing files
- dependency mediation
- We can overwrite the artifact's version by explicitly defining the artifact in our project's pom with the desired version
- If the same artifact is defined with different versions in 2 imported BOMs, then the version in the BOM file that was declared first will win
Gradle
-
What are the advantages of Gradle?
• Declarative builds and build-by-convention- Rich extensible Domain Specific Language (DSL) based on Groovy. Add your own new language elements or enhance the existing ones, thus providing concise, maintainable and comprehensible builds.
• Language for dependency based programming- The declarative language lies on top of a general purpose task graph, which you can fully leverage in your builds. It provides utmost flexibility to adapt Gradle to your unique needs.
• Deep API- From being a pleasure to be used embedded to its many hooks over the whole lifecycle of build execution, Gradle allows you to monitor and customize its configuration and execution behavior to its very core.
• Gradle scales very well.
• Multi-project builds
• Gradle provides partial builds
-
How would you describe the Gradle build lifecycle?
The Gradle build lifecycle is a sequence of phases that Gradle executes when building a project. It consists of four main stages: initialization, configuration, execution, and finalization.
During the initialization phase, Gradle sets up the environment and reads the build script. It then creates a Project instance and a BuildController. The Project instance contains all the information about the project, such as the project name, version, and dependencies. The BuildController is responsible for executing the build tasks.
The configuration phase is where Gradle configures the project. It reads the build script and creates the tasks, source sets, and other objects. It also evaluates the project dependencies and resolves them.
The execution phase is where Gradle executes the tasks. It starts with the root task and then executes the tasks in the order specified in the build script. It also handles task dependencies and parallel execution.
The finalization phase is where Gradle cleans up after the build. It removes any temporary files and performs any other necessary cleanup tasks.
-
What is the difference between a Gradle task and a Gradle plugin?
A Gradle task is a single unit of work that is executed by Gradle. It is typically used to perform a specific action such as compiling source code, running tests, or creating a JAR file. A Gradle plugin is a collection of tasks that are designed to perform a specific set of related tasks. For example, the Java plugin provides tasks for compiling Java source code, running tests, and creating a JAR file. Plugins can also provide additional functionality such as dependency management, code generation, and more.
-
What are Gradle Build Scripts ?
Gradle builds a script file for handling two things, one is projects and another one is tasks. Every Gradle build represents one or more projects. A project represents a library JAR or a web application
-
What is Gradle Wrapper?
The Gradle Wrapper is the preferred way of starting a Gradle build. The wrapper is a batch script on Windows, and a shell script for other operating systems. When we start a Gradle build via the wrapper, Gradle will be automatically downloaded and used to run the build.
-
What are the two types of plugins in Gradle?
- Script Plugins: This provides the additional build script which gives a declarative approach for manipulating the build, and is typically used within a particular build.
- Binary Plugins: These consist of the classes which are responsible for implementing the plugin interface. It adopts a programmatic approach in order to perform manipulation of the build.
-
What is Gradle Daemon?
he Daemon is a long-lived process that helps with the faster build process, by avoiding the cost of JVM startup for every build and also caches information about project structure, files, tasks, and more in memory.
-
How does Gradle achieve faster performance?
Gradle improves build speed by reusing computations from previous builds and also uses cache information.
-
Difference between API and implementation in Gradle.
The API configuration should be used to declare dependencies that are exported by the library API, while the implementation configuration should be used to declare dependencies that are internal to the component.
-
How do you debug a Gradle build?
When debugging a Gradle build, the first step is to enable debug logging. This can be done by adding the --debug flag to the Gradle command line when running the build. This will enable more verbose logging which can help identify the source of the issue.
The next step is to inspect the Gradle build output. This will provide more detailed information about the tasks that are being executed and any errors that are occurring.
If the issue is related to a specific task, it can be helpful to run the task in isolation using the --rerun-tasks flag. This will allow you to focus on the specific task and can help identify the source of the issue.
If the issue is related to a specific plugin, it can be helpful to inspect the source code of the plugin. This can help identify any issues with the plugin configuration or implementation.
Finally, it can be helpful to use a debugging tool such as the Gradle Build Scan plugin. This plugin provides detailed information about the build, including the tasks that are being executed and any errors that are occurring. This can help identify the source of the issue quickly and easily.
-
What is the difference between a Gradle build script and a Gradle build configuration?
A Gradle build script is a Groovy-based script that defines the tasks and configurations of a Gradle project. It is written in the Groovy programming language and is used to define the build logic of a project. The build script is the main entry point for a Gradle project and is used to define the tasks, dependencies, and other configurations of the project.
A Gradle build configuration is a set of properties and settings that are used to configure a Gradle project. It is used to define the project's dependencies, plugins, and other settings. The build configuration is used to define the project's build environment, such as the Java version, the source and target directories, and the build type. It is also used to define the project's dependencies, such as the libraries and frameworks that the project depends on. The build configuration is used to define the project's plugins, such as the plugins used to compile and package the project.
-
How do you configure a Gradle project to use a custom task?
To configure a Gradle project to use a custom task, you must first create the task class. This class should extend the org.gradle.api.DefaultTask class and should be placed in the buildSrc directory of the project. The task class should also include a method annotated with the @TaskAction annotation. This method will contain the logic for the task.
Once the task class is created, you must register the task in the build.gradle file. This is done by adding a task definition to the build.gradle file. The task definition should include the name of the task, the type of the task, and any parameters that the task requires.
Finally, you must add the task to the project. This is done by adding a task dependency to the project. This can be done by using the dependsOn method in the project's build.gradle file.
Spring
Spring Core
Spring Core
-
What is a framework?
A framework is a tool that gives software developers access to prebuilt components or solutions designed to expedite development.
-
What is the best way to inject dependency?
There is no boundation for using a particular dependency injection. But the recommended approach is -
Setters are mostly recommended for optional dependencies injection, and constructor arguments are recommended for mandatory ones. This is because constructor injection enables the injection of values into immutable fields and enables reading them more easily.
-
How we can set the spring bean scope. And what supported scopes does it have?
A scope can be set by an annotation such as the @Scope annotation or the "scope" attribute in an XML configuration file. Spring Bean supports the following five scopes:
- Singleton
- Prototype
- Request
- Session
- Global-session
-
Maven could not locate some of dependencies, what would you do?
-
Method missing error when starting spring boot application?
maven dependency tree
define correct version in dependency management block
Spring AOP
-
Define AOP and its biggest pitfall
Aspect-oriented programming (AOP) is a powerful feature implemented in the Spring framework. It enables developers to define transversal layers to the business logic of an application. Its most common use cases are logging, authorization, and caching.
The most common pitfall that the candidate should be aware of is the probable performance drop when using AOP, as it uses reflection under the hood, and Java reflection isn’t free (direct call to methods is way faster). This can make business logic a little difficult to read to someone who’s skilled in this way of programming.
-
Method is annotated with @Scheduled, and calls another method with @Transactional
Transaction is not created, because we are not calling through proxy. Possible solution - Self Injection
-
If you create pointcut that applies to everything, what will happen?
Most probably program will fail to start because some bean could appear as final, and you couldn’t proxy final beans
Spring Boot
Spring Boot is essentially a framework for rapid application development built on top of the Spring Framework. With its auto-configuration and embedded application server support
Features:
- Starters – a set of dependency descriptors to include relevant dependencies at a go
- Auto-configuration – a way to automatically configure an application based on the dependencies present on the classpath
- Actuator – to get production-ready features such as monitoring
- Security
- Logging
Difference with Spring
Spring Boot makes configuring a Spring application a breeze.
Here are two of the most important benefits Spring Boot brings in:
- Auto-configure applications based on the artifacts it finds on the classpath
- Provide non-functional features common to applications in production, such as security or health checks
Starters
There are more than 50 starters at our disposal. Here, we’ll list the most common:
- spring-boot-starter: core starter, including auto-configuration support, logging and YAML
- spring-boot-starter-aop: for aspect-oriented programming with Spring AOP and AspectJ
- spring-boot-starter-data-jpa: for using Spring Data JPA with Hibernate
- spring-boot-starter-security: for using Spring Security
- spring-boot-starter-test: for testing Spring Boot applications
- spring-boot-starter-web: for building web, including RESTful, applications using Spring MVC
Auto-configuration
SpringBootApplication annotation can be used to enable those three features, that is:
@EnableAutoConfiguration: is used for auto-configuring beans present in the classpath in Spring Boot applications. If we want to disable a specific auto-configuration, we can indicate it using the exclude attribute of the @EnableAutoConfiguration annotation.@ComponentScan: enables Spring to scan for things like configurations, controllers, services, and other components we define.@Configuration: allow to register extra beans in the context or import additional configuration classes
Applications using DevTools restart whenever a file on the classpath changes. This is a very helpful feature in development, as it gives quick feedback for modifications.
Spring Boot Actuator can expose operational information using either HTTP or JMX endpoints. But most applications go for HTTP, where the identity of an endpoint and the /actuator prefix form a URL path.
Here are some of the most common built-in endpoints Actuator provides:
- env exposes environment properties
- health shows application health information
- httptrace displays HTTP trace information
- info displays arbitrary application information
- metrics shows metrics information
- loggers shows and modifies the configuration of loggers in the application
- mappings displays a list of all @RequestMapping paths
Spring MVC supports:
- Tomcat
- Jetty
- Undertow
Spring WebFlux supports:
- Reactor Netty
- Tomcat
- Jetty
- Undertow
Spring Data
-
What the difference between Hibernate And Spring Data JPA?
-
Which policy hibernate uses for collections?
They are lazily loaded by default
-
How @Lazy implemented in spring?
Using proxy
-
[ ] Spring JPA
-
[ ] Spring JDBC
[!info] Introduction to Spring Data MongoDB | Baeldung
A solid intro to using MongoDB in with Spring Data.
https://www.baeldung.com/spring-data-mongodb-tutorial[!info] Uploading Files with Spring MVC | Baeldung
In this article, we focus multipart (file upload) support in Spring MVC web applications.
https://www.baeldung.com/spring-file-upload[!info] Getting Started | Uploading Files
Learn how to build a Spring application that accepts multi-part file uploads.
https://spring.io/guides/gs/uploading-files/ -
[ ] Spring Resources
-
[ ] Spring Core
- [ ] IOC
- [ ] Bean Initialization
- [ ] @Transactional
-
Development
-
[ ] Review
-
[ ] Refactoring
-
[ ] Patterns
-
[ ] Build Tools
-
[ ] Git
-
[ ] CI/CD
-
-
Architecture
-
[ ] Patterns
-
[ ] SOLID
-
[ ] Microservices
-
[ ] Monolith
-
[ ] REST
-
-
Infrastructure
- [ ] Docker
- [ ] K8s
- [ ]
-
Testing
-
Management
-
[ ] Extreme Programming
-
[ ] Kanban
-
[ ] Waterfall
-
[ ] Agile
-
[ ] Scrum
-
Spring MVC
Spring Security
[!info] Spring Security Custom Logout Handler | Baeldung
Learn how to implement a Custom Logout Handler using Spring Security.
https://www.baeldung.com/spring-security-custom-logout-handler
[!info]
https://www.interviewbit.com/spring-security-interview-questions/?utm_source=pocket_saves

Spring Tests
[!info] Testing in Spring Boot | Baeldung
Learn about how the Spring Boot supports testing, to write unit tests efficiently.
https://www.baeldung.com/spring-boot-testing
Integratrion tests
When running integration tests for a Spring application, we must have an ApplicationContext.
@SpringBootTest - creates an ApplicationContext from configuration classes indicated by its classes attribute. In case the classes attribute isn’t set, Spring Boot searches for the primary configuration class.The search starts from the package containing the test until it finds a class annotated with @SpringBootApplication or @SpringBootConfiguratio
Spring Cloud
[!info]
https://www.interviewbit.com/spring-interview-questions/?sign_up_medium=ib_article_auth_blocker
[!info] Top Spring Framework Interview Questions | Baeldung
A quick discussion of common questions about the Spring Framework that might come up during a job interview.
https://www.baeldung.com/spring-interview-questions
[!info] bliki: Inversion Of Control
a bliki entry for Inversion Of Control
http://martinfowler.com/bliki/InversionOfControl.html
- What is IoC?
- What is Dependency Inversion?
- What is Dependency Injection?
- Explain the concepts of coupling and cohesion and how they relate to maintainability. As a follow-up, please explain afferent coupling and efferent coupling, and how those concepts fit above.
../Java/Frameworks/Spring/Spring
Algorithms
-
Tail recursion is functionally equivalent to iteration. Since Java does not yet support tail call optimization, describe how to transform a simple tail recursive function into a loop and why one is typically preferred over the other.
Here is an example of a typical recursive function, computing the arithmetic series 1, 2, 3…N. Notice how the addition is performed after the function call. For each recursive step, we add another frame to the stack.
public intsumFromOneToN(int n) { if (n < 1) { return 0; } return n + sumFromOneToN(n - 1); }Tail recursion occurs when the recursive call is in the tail position within its enclosing context - after the function calls itself, it performs no additional work. That is, once the base case is complete, the solution is apparent. For example:
public int sumFromOneToN(int n, int a) { if (n < 1) { return a; } return sumFromOneToN(n - 1, a + n); }Here you can see that
aplays the role of the accumulator - instead of computing the sum on the way down the stack, we compute it on the way up, effectively making the return trip unnecessary, since it stores no additional state and performs no further computation. Once we hit the base case, the work is done - below is that same function, “unrolled”.public intsumFromOneToN(int n) { int a = 0; while(n > 0) { a += n--; } return a; }Many functional languages natively support tail call optimization, however the JVM does not. In order to implement recursive functions in Java, we need to be aware of this limitation to avoid
StackOverflowErrors. In Java, iteration is almost universally preferred to recursion.
[!info] Explore - LeetCode
LeetCode Explore is the best place for everyone to start practicing and learning on LeetCode.
https://leetcode.com/explore/interview/card/cheatsheets/720/resources/4725/
-
Explain the Big O notation
Big O notation allows developers to analyze how long an algorithm takes to run or the memory required. It effectively describes the complexity of code, relying on algebraic terminology. Generally, it’s used to define the limiting behavior of functions when arguments tend toward a specific value or infinity, serving as an upper bound.
Discussing your experience with Big O notation can give the hiring manager more insights into your capabilities, so feel free to follow up the definition with an applicable example. Here’s one in our collection of backend developer interview questions comparing LinkedList and ArrayList in Java using Big O notation.

-
What could be the tradeoff between the usage of an unordered array versus the usage of an ordered array?
- The main advantage of having an ordered array is the reduced search time complexity of
O(log n)whereas the time complexity in an unordered array isO(n). - The main drawback of the ordered array is its increased insertion time which is O(n) due to the fact that its element has to reordered to maintain the order of array during every insertion whereas the time complexity in the unordered array is only O(1).
- Considering the above 2 key points and depending on what kind of scenario a developer requires, the appropriate data structure can be used for implementation.
- The main advantage of having an ordered array is the reduced search time complexity of
[!info] Core Java Interview Questions and Answers (2024) - InterviewBit
Learn and Practice on almost all coding interview questions asked historically and get referred to the best tech companies
https://www.interviewbit.com/java-interview-questions/#java-program-to-check-palindrome-string-using-recursion
Sorting algorithms
All major programming languages have a built-in method for sorting. It is usually correct to assume and say sorting costs O(n * logn) is the number of elements being sorted. For completeness, here is a chart that lists many common sorting algorithms and their completeness.

Search algorithms
Data Structures

Here's an example of a task:
- There is a Pojo class.
- It has two fields: value and length, as well as getters and setters.
- Getters and setters for the second field are commented.
- We need to use this entity as a key in the HashMap.
- Also, using it we need to save Integer Object.
- For Pojo we setValue "abc" and record it to the HashMap.
- Then, setLength and try to return it.
Question: what will be returned as a result?
class Pojo{
private String value;
private Integer length;
public String getValue(){
return value;
}
public void setValue(String value){
this.value = value;
}
//getter, setter for length
public static void main(String[] args){
Map<Pojo, Integer> map = new HashMap();
Pojo key = new Pojo();
key.setValue("abc");
map.put(key, 1);
key.setLength(3);
Integer result = map.get(key);
System.out.println(result);
}
}
|
This question is quite simple but extensive. Candidates of any seniority level will find something to offer as an answer.
Candidates frequently think that the answer to this task is "1". Their argument: hashcode equals is not overridden and will be used from the basic class, Object, which doesn't have mentioned fields. In response to this answer, the interviewer may ask: how can we change the Pojo class so that this code works for us on the client-side?
Most candidates suggest defining equals and hashcode. Once we have defined equals and hashcode, we will always get "null". Null will be returned just because we changed the Length and an Object is mutable.
Though it's not a difficult question, some candidates need to iterate over the code, go through all the points, calculate, and see that hashcode will get modified and we will not find an Object.
This leads to the problem of immutability, and the goal of identifying the ways to safely use Pojo. A candidate might suggest using finals at the beginning, because there is no access modifier.
final class Pojo{
private String value;
private Integer length;
public String getValue(){
return value;
}
public void setValue(String value){
this.value = value;
}
//getter, setter for length
//hascode and equals
public static void main(String[] args){
Map<Pojo, Integer> map = new HashMap();
Pojo key = new Pojo();
key.setValue("abc");
map.put(key, 1);
key.setLength(3);
Integer result = map.get(key);
}
}
When this class becomes immutable, the task can be slightly changed: Instead of the string value, let's insert a mutable Object, for example, Date or another mutable class. Then the questions are: what will happen now, how will this work, and is there any problem?
The candidate may suggest using either copying or cloning. If so, it might be a good idea to play around with cloning and exceptions as necessary. Cases are different and candidates may resolve this task differently as well.
final class Pojo{
private final Date value;
private final Integer length;
public Pojo(Date value, Integer length) {
this.value = value;
this.length = length;
}
public Date getValue(){
return value;
}
//getter for length, equals, hashcode
public static void main(String[] args){
Map<Pojo, Integer> map = new HashMap();
Pojo key = new Pojo(new Date(), 3);
map.put(key, 1);
key.getValue().setTime(123);
Integer result = map.get(key);
}
}
This is how the interviewer may cover data structures using the example of HashMap, which is probably the most commonly used. If a candidate is open to talking about algorithmic problems, the interviewer may suggest taking a look at the nuances of HashMap.
In any case, any advanced Java interview questions within a practical task are designed to respond to a candidate's experience and interest. The interviewer's aim is not so much to spot knowledge gaps as it is to reveal areas that a candidate is interested in and evaluate the depth and breadth of their knowledge.
Interviewers say that a readiness to get to the code is one of the key skills to check. This helps to assess how a candidate may deal with an unknown problem or a new task moving forward.
- Given a stream of Arabic numerals. Find the one that occurs maximum times.
- Reverse a linked list during an interview
- Convert a binary tree into a doubly linked list during an interview
- Find a loop in a linked list during an interview
- Sort an array of integers during an interview
- Search an element in a sorted and shifted array during the interview (5, 6, 1, 2, 3)
- What is an in-place sorting algorithm?
- Write an algorithm to rotate an image 90 degrees clockwise
- What is an NP problem? How to identify it?
- What is O(n) notation? Come up with some examples
- What is a hash collision? What are the ways to handle it?
- What is a good hash function?
- Describe a Travelling Salesman Problem
- What is dynamic programming?
- What is memoization?
- Find intersection between 3 sorted arrays: [2,6,7,8], [3,6,8,10], [4,5,6,8] => [6,8]
- Generate a sequence of unique random numbers.
- What is a priority queue?
- What is a heap?
- What is B-tree?
- What is 2-3-tree?
- What is RB-tree? What is AVL-tree?
- What is Set?
- What are HashMap and HashSet? Difference between them
- Implement a linked list during an interview
- Implement a graph during an interview
Architecture
Web Architecture
-
[ ] Web Sockets
-
What are the pros and cons of microservices?
The pros to mention:
- Microservices architecture is highly scalable, in a flexible way.
- It is easy to understand.
- It helps to avoid fault isolation.
- It ensures fast recovery in case of the right design and use of orchestration.
- It offers faster deployment if CD is well-set and fine-tuned.
The cons to mention:
- There is complex communication between services (requiring an HTTP code, a queue, etc.).
- More services require more resources.
- Debugging and end-to-end testing are more complex in microservices.
- Deployment might be challenging if the team is not quite mature in terms of DevOps practices, and can't set up the CD process properly.
-
What are the common patterns related to microservices?
Another important area of knowledge regarding microservices is patterns. It's helpful if a candidate can go beyond API Gateway and Circuit Breaker and cover more patterns related to microservices architecture.
Patterns fall into different categories: decomposition patterns (decomposing monolith into microservices), patterns that enable integration between services, database-related patterns, patterns for transactions, observability of microservice states, and more.
Senior candidates are also expected to demonstrate at least a general understanding of logging, monitoring, and alerting. A few essential aspects include:
- Logging: tools, ELK and Splunk stacks, how logging aggregation works, and how it's implemented in general.
- Monitoring: here, the interviewer expects to hear about automation, capturing and measuring various metrics (e.g. latency requests, open tracing), possible bottlenecks, and ways to address them quickly and efficiently.
- Alerting: regarding this pattern, which relates to monitoring, it's important to talk about automation, tools, and how to implement alerting.
-
REST vs SOAP
I’ll uncover one of my favorite questions to ask during interviews, especially with experienced candidates who’ve probably used SOAP in legacy projects.
It’s possible to compare these two web service technologies from different angles. The theoretical differences, such as “SOAP is a protocol and REST is not,” while certainly interesting, do not have a lot of value when it comes to checking the real experience of a candidate. Something that is usually not mentioned during comparisons and that can help detect if the candidate has real experience with both, is the use of Web Service Definition Language (WSDL) files.
WSDL files are usually used to generate communication STUBs in Java. Is there any tool or technology that helps us do the same with REST endpoints? The answer is yes, and it’s called OpenAPI. Documenting web services is one of the most important things to do when providing functionality. Make sure you know how to document your APIs with both Rest and SOAP endpoints!
-
What are the limitations of GET?
The GET method in HTTP should be used only to retrieve resources from a web server, without altering the state of the application in any way. An exception to this is when we have caching. In this case, a slight modification to the state of the application might be tolerable.
Limitations of GET usually regard the fact that the method cannot theoretically have a request body, so every parameter should be included in the URL, and the URL has a limited length (~2K characters). In practice, it is possible to send a body with the GET method even if this is not a good practice and should be avoided.
With 2K characters available, we are certain to have all the input needed to retrieve a resource from a web server.
Something very important to know about is Microservices. There are many frameworks out there that will help you build, deploy, monitor and interact with Microservices. Master at least one REST framework (Spring Boot, Play, DropWizard etc.). Make sure you are aware of concepts like scaling and resilience, event-driven architectures, and asynchronous logging, as well as having a conceptual understanding of REST. Having said that, know at least the basics about containers (e.g. Docker), clouds (e.g. AWS), build systems, and continuous delivery.
-
Distributed systems / Microservices
- Event-driven
- Circuit breaker
- Saga
- CQRS
-
API Design
- What makes a good API design, and why is it important?
- How can RESTful principles be applied to design scalable and maintainable APIs?
-
Monitoring and Logging
- Why is monitoring crucial in system design, and what tools and techniques are available for system monitoring?
- How can logging be effectively implemented to facilitate debugging and system analysis?
-
Continuous Integration/Continuous Deployment (CI/CD)
- How does CI/CD contribute to effective system design and development workflows?
- What are the key principles of CI/CD, and how can they be implemented?
-
Deployment Strategies
- Explore different deployment strategies, such as blue-green deployment, canary release, and rolling deployment.
- How do these strategies contribute to system availability and maintainability?
-
Spring Framework / Spring Boot
- Design patterns implemented in Spring (Proxy, Factory, Strategy, Chain of responsibility)
- Spring Boot autoconfiguration and starters
-
Optional: Cloud (Amazon Web Services)
- SQS, SNS
- DynamoDB, Aurora
- Lambdas
- System design and analysis
-
Microservices vs. Monolith:
- Compare and contrast microservices architecture with monolithic architecture.
- When is it appropriate to choose a microservices architecture, and what are the benefits and challenges associated with it?
-
Databases and Data Storage:
- How do you choose the right database for a given application? Consider relational databases, NoSQL databases, and in-memory databases.
- Discuss strategies for data modeling, normalization, and denormalization.
-
Scalability and Performance:
- What are the key considerations for designing a scalable system?
- How can systems be optimized for performance, and what role do caching and load balancing play in scalability?
-
Security in System Design:
- What are the fundamental principles of designing a secure system?
- How can you protect against common security threats, such as SQL injection, cross-site scripting (XSS), and cross-site request forgery (CSRF)?
-
Fault Tolerance and Reliability:
- How can a system be designed to be fault-tolerant and reliable?
- Discuss strategies for handling failures, implementing redundancy, and ensuring system availability.
-
Communication Protocols:
- Explore different communication protocols used in system design, such as HTTP/HTTPS, WebSocket, and message queues.
- How do these protocols contribute to the efficiency and responsiveness of a system?
-
Concurrency and Parallelism:
- Discuss the challenges and solutions related to handling concurrency in a distributed system.
- How can parallelism be leveraged for performance improvements?
-
Caching Strategies:
- What role does caching play in system design, and what are common caching strategies?
- How can caching be used to improve response times and reduce the load on databases?
-
Cost Optimization:
- How can system design impact the cost of infrastructure and operations?
- Discuss strategies for optimizing costs, especially in cloud-based architectures.
-
Elasticity and Auto-scaling:
- What is elasticity in the context of system design, and how does auto-scaling work?
- How can systems dynamically adapt to varying workloads to ensure optimal resource utilization?
-
Design an Instagram
-
SOLID
-
What are GoF design patterns? Why should you care?
-
What's can go wrong with Active Record pattern?
-
What do you think about
null? How to avoid it? -
What is composition over inheritance?
-
What should you return concrete implementation or abstraction? E.g.
ListorIList? When you would pick one approach over another? Think about performance as well. -
What is the difference between IoC and service locator?
-
Name a few anti-patterns
-
What is MVC? Explain it using ASP.NET example. Define responsibilities.
-
What is MVVM? Define responsibilities for each component.
-
Layered architecture
-
Explain pub/sub to me
-
What is CQS and how it relates to CQRS?
-
What is a command in CQRS terms?
-
What is the difference between command and event?
-
What command handler is and what it does?
-
Which type of projects is the best to introduce CQRS?
-
Difference between stateful and stateless service.
-
What is the blue DDD book?
-
What is DDD?
-
What is the domain model?
-
What is the anemic domain model? Is it useful?
-
What is the bounded context? How to identify a bounded context? Describe the example of two bounded contexts in terms of the same domain.
-
What is the difference between a bounded context and a subdomain?
-
Aggregate, AggregateRoot, Entity, ValueObject - what are those? Describe the difference between them
-
What is an ubiquitous language? Why is that important?
-
Immutability - what is that? Should commands or events be immutable?
-
What is saga? Come up with a real-world example to explain sagas.
-
What is event sourcing?
-
What is snapshotting in terms of event sourcing?
-
What is a projection?
-
Describe the role of aggregate in CQRS/ES/DDD environment. Go deep on two-phase commit on writing an event to the event store and publishing event to a bus. Are transactions good candidates for that kind of case? If not, how to avoid transactions in that case?
-
Can you send a command to another bounded context in CQRS/ES/DDD environment? Can you publish an event to another bounded context in CQRS/ES/DDD environment?
-
What is AOP? Which parts of the system would you move to aspects?
-
- What is CorrelationId?
- When a retry policy is suitable in general? When should you retry your command/API call?
-
How to design against vendor lock-in?
[!info] Microservices vs. monolithic architecture | Atlassian
While a monolithic application is a single unified unit, a microservices architecture is a collection of smaller, independently deployable services.
https://www.atlassian.com/microservices/microservices-architecture/microservices-vs-monolith
[!info] Backend Developer Roadmap: What is Backend Development?
Learn what backend development is, what backend developers do and how to become one using our community-driven roadmap.
https://roadmap.sh/backend
[!info] Correctness (computer science)
In theoretical computer science, an algorithm is correct with respect to a specification if it behaves as specified.
https://en.wikipedia.org/wiki/Correctness_(computer_science)
[!info] UsingAndAvoidingNullExplained
Google core libraries for Java.
https://github.com/google/guava/wiki/UsingAndAvoidingNullExplained
Performance
-
How to identify performance issues in an application?
Typically, performance issues are reported by testers or users sometime after a feature has been shipped to production. Identifying the root cause of the issue can be difficult, so this is a good interview question for experienced candidates.
The first step in identifying and resolving a performance issue is measuring the actual performance of the behavior. Only then can an optimization make any sense, otherwise the enhancement cannot be measured.
Identification of the precise piece of the business logic to optimize may occur manually by inserting logs measuring time, or by using profiling tools that automatically decouple the various pieces of the flow measuring time spent in the execution.
When asked this senior Java developer interview question, experienced candidates may also want to describe one of the hardest performance issues they have faced, or trivial issues that can be easily avoided by adopting a series of good practices and keeping an eye on performance during the whole development lifecycle.
-
How to handle huge data on Redis cache?
The candidate’s first reaction to this question should be, “Does it make sense to have huge data on Redis?” A distributed cache is built primarily to enhance the performance of a distributed microservice application. Together with the physical limit of the RAM available for the Redis host, there is a software limit on a single item of 512MB. To store a huge data load, we should be able to split it into chunks and retrieve results, for example by using the HGETALL command. Compression before storing the data might also be an option.
Generally speaking, Redis was not built to achieve this. Retrieving vast chunks of data has been indicated as one of the worst practices. A way better solution could be to store the data object in a standard NoSQL database.
The goal of this interview question is to check the previous experience of senior Java developer candidates, with a focus on how they propose new solutions instead of sticking to the plan.
-
What is Service Level Agreement?
Message Queues
Producers and consumers are decoupled via brokers, and this enables scalability.
[!info] Top 50 Kafka Interview Questions And Answers for 2024
In this article, we have compiled over 50 most frequently asked Kafka interview questions that can help you crack your next Kafka interview.
https://www.simplilearn.com/kafka-interview-questions-and-answers-article
[!info] Asynchronous Messaging Patterns
Asynchronous messaging enables applications to decouple from one another to improve performance, scalability, and reliability.
https://blogs.mulesoft.com/migration/asynchronous-messaging-patterns/
-
Delivery semantics
Delivery semantics define how streaming platforms guarantee the delivery of events from source to destination in our streaming applications.
There are three different delivery semantics available:
-
at-most-once
In this approach, the consumer saves the position of the last received event first and then processes it.
Considering the example of Apache Kafka, which uses offsets for messages, the sequence of the At-Most-Once guarantee would be:
- persist offsets
- persist results
In order to enable At-Most-Once semantics in Kafka, we’ll need to set “enable.auto.commit” to “true” at the consumer
If there’s a failure and the consumer restarts, it will look at the last persisted offset. Since the offsets are persisted prior to actual event processing, we cannot establish whether every event received by the consumer was successfully processed or not. In this case, the consumer might end up missing some events.

-
at-least-once
In this approach, the consumer processes the received event, persists the results somewhere, and then finally saves the position of the last received event.
Unlike at-most-once, here, in case of failure, the consumer can read and reprocess the old events.
In some scenarios, this can lead to data duplication. Let’s consider the example where the consumer fails after processing and saving an event but before saving the last known event position (also known as the offset).
The consumer would restart and read from the offset. Here, the consumer reprocesses the events more than once because even though the message was successfully processed before the failure, the position of the last received event was not saved successfully:

In order to avoid processing the same event multiple times, we can use idempotent consumers.
Essentially an idempotent consumer can consume a message multiple times but only processes it once.
The combination of the following approaches enables idempotent consumers in at-least-once delivery:
- The producer assigns a unique messageId to each message.
- The consumer maintains a record of all processed messages in a database.
- When a new message arrives, the consumer checks it against the existing _messageId_s in the persistent storage table.
- In case there’s a match, the consumer updates the offset without re-consuming, sends the acknowledgment back, and effectively marks the message as consumed.
- When the event is not already present, a database transaction is started, and a new messageId is inserted. Next, this new message is processed based on whatever business logic is required. On completion of message processing, the transaction’s finally committed
In Kafka, to ensure at-least-once semantics, the producer must wait for the acknowledgment from the broker.
The producer resends the message if it doesn’t receive any acknowledgment from the broker.
Additionally, as the producer writes messages to the broker in batches, if that write fails and the producer retries, messages within the batch may be written more than once in Kafka.
However, to avoid duplication, Kafka introduced the feature of the idempotent producer.
Essentially, in order to enable at-least-once semantics in Kafka, we’ll need to:
- set the property “ack” to value “1” on the producer side
- set “enable.auto.commit” property to value “false” on the consumer side.
- set “enable.idempotence” property to value “true“
- attach the sequence number and producer id to each message from the producer
Kafka Broker can identify the message duplication on a topic using the sequence number and producer id.
-
exactly-once
This delivery guarantee is similar to at-least-once semantics. First, the event received is processed, and then the results are stored somewhere. In case of failure and restart, the consumer can reread and reprocess the old events. However, u****nlike at-least-once processing, any duplicate events are dropped and not processed, resulting in exactly-once processing.
The sequence proceeds as follows:
- persist results
- persist offsets
Let’s see what happens when a consumer fails after processing the events but without saving the offsets in the diagram below:

We can remove duplication in exactly-once semantics by having these:
- idempotent updates – we’ll save results on a unique key or ID that is generated. In the case of duplication, the generated key or ID will already be in the results (a database, for example), so the consumer can remove the duplicate without updating the results
- transactional updates – we’ll save the results in batches that require a transaction to begin and a transaction to commit, so in the event of a commit, the events will be successfully processed. Here we will be simply dropping the duplicate events without any results update.
Let’s see what we need to do to enable exactly-once semantics in Kafka:
- enable idempotent producer and transactional feature on the producer by setting the unique value for “transaction.id” for each producer
- enable transaction feature at the consumer by setting property “isolation.level” to value “read_committed“
-
Possible issues
There are two important considerations in the message delivery platforms:
- accuracy
- latency
Produces failures can lead to some issues:
- After a message is generated by the producer, it may fail before sending it over the network. This may cause data loss.
- The producer may fail while waiting to receive an acknowledgment from the broker. When the producer recovers, it tries to resend the message assuming missing acknowledgment from the broker. This may cause data duplication at the broker.
There can be a network failure between the producer and broker:
- The producer may send a message which never gets to the broker due to network issues.
- There can also be a scenario where the broker receives the message and sends the acknowledgment, but the producer never receives the acknowledgment due to network issues.
Similarly, broker failures can also cause data duplication:
- A broker may fail after committing the message to persistent storage and before sending the acknowledgment to the producer. This can cause the resending of data from producers leading to data duplication.
- A broker may be tracking the messages consumers have read so far. The broker may fail before committing this information. This can cause consumers to read the same message multiple times leading to data duplication.
There may be a failure during writing data to the disk from the in-memory state leading to data loss.
There can be network failure between the broker and the consumer:
-
The consumer may never receive the message despite the broker sending the message and recording that it sent the message.
-
Similarly, a consumer may send the acknowledgment after receiving the message, but the acknowledgment may never get to the broker.
-
The consumer may fail before processing the message.
-
The consumer may fail before recording in persistence storage that it processed the message.
-
The consumer may also fail after recording that it processed the message but before sending the acknowledgment.
Cloud
[!info]
Environment
Git
When it’s not possible to merge two branches because of conflicts, developers have two options: merging or rebasing. A rebase may be needed when reserving a clean Git history is important. Rebasing means to move the base of a branch on top of the leaf of another. Instead of having branches intersect multiple times, you can have a clean Git history, as long as everyone follows the golden rule of rebasing: never rebase a public branch.
Stashing is a powerful tool to put aside code that you just wrote, without pushing it to any remote tracked branch. While it’s possible to create multiple stashes at once by giving them different names, it’s usually better to not have more than one stash, as things can become complex to restore. Is there any difference between creating a local git branch and a git stash?
[!info] Documentation | Terraform | HashiCorp Developer
Documentation for Terraform, including Terraform CLI, Terraform Cloud, and Terraform Enterprise.
https://developer.hashicorp.com/terraform/docs
[!info] DevOps Roadmap: Learn to become a DevOps Engineer or SRE
Learn to become a modern DevOps engineer by following the steps, skills, resources and guides listed in our community-driven roadmap.
https://roadmap.sh/devops
Security
-
What security standards do you know?
- International Organization for Standardization (ISO) 27034
- Center for Internet Security (CIS) Control 16: Application Software Security
- Payment Card Industry (PCI) Payment Application Data Security Standard (PA-DSS)
- OWASP Application Security Verification Standard (ASVS)
- National Institute of Technologies (NIST) Special Publication (SP) 800–218 (DRAFT)
- CWE (Common Weakness Enumeration)
- MISRA-C (Motor Industry Software Reliability Association) for the C programming language.
- HIPAA (Health Insurance Portability and Accountability Act)
- The Web Application Security Consortium (WASC)
-
How do you prevent sensitive data exposure?
Sensitive data is highly confidential information that has to be kept secure and unavailable to those without authorization. Sensitive data comprises information such as people's home addresses, salaries, customer data, credit/debit card data, and information that should be protected in case of a data breach.You can prevent exposure by:
- Deleting all sensitive data once it has served its purpose
- Encrypting all the sensitive data you hold
- Using security testing tools to catch issues early
- Predicting the threats you may face and preparing for or defending against them
- Disabling caching and autocomplete forms that contain or collect sensitive background information
- Using cloud services like KeyVault in Azure or KMS in AWS
- Using strong passwords and ciphers
- Classifying data
-
Name OWASP Top 10 Security Flaws
- Injection
- Sensitive data exposure
- Broken authentication
- Broken access control
- XXE injection
- Security misconfiguration
- Insecure deserialization
- Cross-site scripting
- Insufficient logging and monitoring
- Using components with known vulnerabilities
-
What software security protection methods do you know?
There are numerous software protection methods. Some options you could discuss include:
- Code signing certificates
- Error handling
- Hashing passwords
- Input sanitization
- User authentication
- Whitelisting
With this question, you’ll want to outline your personal experience regarding software security. The phrasing of the question is broad enough to allow you to steer your answer in any appropriate direction.
-
[ ] Web Server Security
System Design
-
Name API architectural approaches
Here is an overview of some API architectural styles:
- Event-driven
- Hypermedia
- Pragmatic REST
- Web API
-
In what cases is a microservices architecture better than a monolithic one?
Because a microservices architecture is made up of pieces that run separately, each service may be built, upgraded, distributed, and scaled independently of the others. Software upgrades may be carried out more often, resulting in higher dependability, availability, and performance.
-
What is CORS?
CORS, or cross-origin resource sharing, is an HTTP-header-based mechanism that lets a server define origins outside of itself where the browser should allow the loading of resources. Within CORS is a mechanism that ensures browsers reach out before a user request to confirm the server will support the request for the cross-origin resource.
If you have an example from a past project that involved CORS, discuss it to give your answer more depth.
Я принес. Подготовка к system design собеседованиям
Собеседования по system design – это стандартная практика в многих бигтехах и у тех, кто под них мимикрирует. И прохождение этих собеседований является отдельным навыком, требующим подготовки.
Это я вам точно скажу на своем опыте: в прошлом году не готовился особо и провалил несколько таких собесов, а в этом готовился и успешно прошел несколько таких собесов. Некоторые из пройденных были даже в тех же компаниях, в которых провалил в прошлом году.
Перейдем к материалам.
Серия видеозаписей, подробно объясняющих, что и как делать:
⁃ https://www.youtube.com/watch?v=Cth-B4r_pf4
⁃ https://www.youtube.com/watch?v=Be7INI_U6GY
⁃ https://www.youtube.com/watch?v=jUbOm0B-eKQ
⁃ https://www.youtube.com/watch?v=Wh5Ya6UFG1k
Статьи:
⁃ https://stefaniuk.website/tags/system-design/
⁃ https://github.com/donnemartin/system-design-primer/
⁃ https://habr.com/ru/companies/avito/articles/753248/
⁃ https://github.com/vitkarpov/coding-interviews-blog-archive\#system-design
⁃ https://habr.com/ru/companies/yandex/articles/564132/
Книги:
⁃ https://www.litres.ru/book/aleks-suy/system-design-podgotovka-k-slozhnomu-intervu-67193183/
Смотрите видео, читайте и конспектируйте статьи и книги. Для пущей уверенности мо
Code quality
Clean Code
-
What types of code smells do you know?
- Bloaters: Long Method, Primitive Obsession, Long Parameter List, Oddball Situations, Data Clumps, Class Doesn’t Do Much, Required Setup/Teardown Code, etc.
- Obfuscator: Poor Names, Vertical Separation, Comments, Regions, Inconsistency, Obscured Intent, etc.
- Change preventers: Shotgun Surgery, Poorly Written Tests, Parallel Inheritance Hierarchies, Divergent Change, Inconsistent Abstraction Levels, Conditional Complexity, etc.
- Couplers: Tramp Data, Artificial Coupling, Middle Man, Feature Envy, Indecent Exposure, Hidden Dependencies, Law of Demeter Violations, Inappropriate Intimacy, Hidden Temporal Coupling, etc.
- Dispensables: Dead Code, Lazy Class, Duplicate Code, Speculative Generality, Data Class, etc.
- Test smells: The Nitpicker, The Greedy Catcher, The Sequencer, Fragility, Not Enough Tests, Dry v. Damp, The Loudmouth, The Enumerator, The Mockery, The Giant, The Hidden Dependency, The Void, Hidden Tests, Wait and See, The One, Roll the Dice, etc.
-
How do you prevent technical debt?
The projected cost of redesigning software is referred to as technical debt. It results from using simple, constrained solutions during software development to save production time. To prevent this, some measures can be taken:
- Create proper documentation before beginning any project to ensure that fixes, tests, and implementation are all accounted for. Update this documentation regularly.
- Use agile development approaches to achieve speed without taking shortcuts while having the valuable ability to make relevant modifications as the project continues.
- Choose or put together a team of developers that you can trust to always deliver what is needed. Competent developers make it easy to collaborate with minimal friction and mistakes.
- It is important not to give in to the temptation to save money and time. The tradeoff is not worth it. Quality should always be king if you don’t want to go back and make changes after the fact.
- Testing is important and must be established in every stage with a checklist of milestones and modifications to complete before moving to the next stage.
- An annual system maintenance plan is crucial for a senior software engineer to succeed.
-
[ ] Clean Code
Patterns
Design Patterns
-
What is the best Singleton implementation? Why?
singleton class using an inner static helper class. - When the singleton class is loaded,
SingletonHelperclass is not loaded into memory and only when someone calls thegetInstance()method, this class gets loaded and creates the singleton class instance. This is the most widely used approach for the singleton class as it doesn’t require synchronization. But it may be broken by reflectionprivate static class SingletonHelper { private static final BillPughSingleton INSTANCE = new BillPughSingleton(); } public static BillPughSingleton getInstance() { return SingletonHelper.INSTANCE; }Enum couldn’t be broken by reflection, but is somewhat inflexible (for example, it does not allow lazy initialization).
-
Which problems may accure in Lazy Singleton?
it can cause issues if multiple threads are inside the
ifcondition at the same time.public class LazyInitializedSingleton { private static LazyInitializedSingleton instance; private LazyInitializedSingleton(){} public static LazyInitializedSingleton getInstance() { if (instance == null) { instance = new LazyInitializedSingleton(); } return instance; } }To fix this we have
public static synchronized ThreadSafeSingleton getInstance() { if (instance == null) { instance = new ThreadSafeSingleton(); } return instance; }Or faster
if (instance == null) { synchronized (ThreadSafeSingleton.class) { if (instance == null) { instance = new ThreadSafeSingleton(); } } } -
Why singleton is antipattern?
- They are generally used as a global instance, why is that so bad? Because you hide the dependencies of your application in your code, instead of exposing them through the interfaces. Making something global to avoid passing it around is a code smell.
- It doesn’t align to single responsibility principle. It manages some logic and responsible to have only one instance. They violate the single responsibility principle: by virtue of the fact that they control their own creation and lifecycle.
- They inherently cause code to be tightly coupled. This makes faking them out under test rather difficult in many cases.
- They carry state around for the lifetime of the application
Microservices Patterns
Design and Development Principles
- System Design Exercise 1 (30 minutes):
- Introduce the Problem statement to the candidate providing minimum information.
- Allow the candidate to clarify the details, ask additional questions, work through the problem, and explain their thought process.
- Add some complexity to the problem statement during the conversation
-
Algorithms and Data Structures (15 minutes):
- Pose questions related to algorithms and data structures including both time and space complexities.
- Evaluate problem-solving skills and understanding of core concepts. (ask about use cases)
-
Programming Languages (15 minutes):
- Assess the candidate's proficiency in relevant programming languages.
- Focus on knowing and understanding:
- Object-Oriented Programming (OOP): (principles of OOP, including encapsulation, inheritance, and polymorphism)
- Collections: (List, Set, and Map, their implementation and internal structure)
- Multithreading and Concurrency: (threads management, synchronization, and concurrent programming concepts)
- Java Memory Management: (GC**:** types, how they work, Memory Leaks)
- Functional Programming: (key concepts and characteristics, use-cases )
-
Coding Exercise 1 (15 minutes):
- Present a coding task that should be solved using Java 8+ approaches (encourage to use Stream, Functional Interface, Method reference, Lambda and ask about implementation details)
- Allow the candidate to work through the problem, explaining their thought process.
- Please encourage them to write code following Clean Code principles or ask them to review their code and improve.
-
Coding Exercise 2( 30 minutes):
- Present a coding task related to the role(A3 medium, A4 hard) Note: Adjust the complexity of the task based on their performance. If the candidate is demonstrating a strong understanding, consider introducing more challenging aspects. On the other hand, if they are facing difficulties, feel empowered to simplify the task to ensure a fair evaluation.
- Allow the candidate to work through the problem, explaining their thought process.
- Please encourage them to write code following Clean Code principles or ask them to review their code and improve. What needs to be changed to ensure this code is ready for production?
- https://videoportal.epam.com/video/wJWrlKY1
- [ ] https://videoportal.epam.com/video/L7xD9674
- [ ] https://videoportal.epam.com/video/V7ggkO70
- [ ] https://martinfowler.com/tags/2023.html
- [ ] https://medium.com/javarevisited/top-10-microservice-design-patterns-for-experienced-developers-f4f5f782810e
- [ ] https://medium.com/@madhukaudantha/microservice-architecture-and-design-patterns-for-microservices-e0e5013fd58a
- [ ] https://microservices.io/patterns/microservices.html
- [ ] https://levelup.gitconnected.com/12-microservices-pattern-i-wish-i-knew-before-the-system-design-interview-5c35919f16a2
- [ ] https://videoportal.epam.com/video/ba2W1KYk
- [ ] https://www.atlassian.com/devops/frameworks/calms-framework#:~:text=CALMS is a framework that,Lean%2C Measurement%2C and Sharing.
- [ ] https://www.perforce.com/blog/sca/what-code-quality-overview-how-improve-code-quality
- [ ]
- [ ] Code quality

-
[ ] Design and Development Principles

-
[ ] Architectural Patterns

Sample 1: URL Shortening Service
Problem: Design a URL shortening service like Bitly.
Solution:
- Use a relational database to store mappings between short and long URLs.
- Generate a short URL using a unique identifier or a hashing algorithm.
- Implement a caching mechanism for frequently accessed URLs.
- Ensure scalability and availability by distributing the service across multiple servers.
Sample 2: Social Media Feed System
Problem: Design a system to generate and display a user's social media feed.
Solution:
- Use a microservices architecture with services for user management, post creation, and feed generation.
- Store user posts in a scalable and distributed database.
- Implement a feed generation algorithm based on relevance, recency, and user interactions.
- Use a caching layer to optimize feed retrieval.
Sample 3: Online Marketplace
Problem: Design an online marketplace where users can buy and sell products.
Solution:
- Use a microservices architecture with services for user management, product listing, order processing, and payment.
- Implement a search and recommendation engine for product discovery.
- Ensure secure and reliable payment processing using a payment gateway.
- Use a scalable database to store product information and user transactions.
These sample problems and solutions cover a range of difficulty levels and demonstrate both algorithmic problem-solving skills and system design considerations. Keep in mind that real-world scenarios may involve more complexity and trade-offs.
- LINQ, lazy execution, EF limitations.
- scalable application development
- What are WebSockets? Where can you use them?
- What is the difference between polling and long polling in sockets?
Relational Databases
-
RDBMS
-
How can you find duplicates in a relational database by using SQL?
At the service level, there's a task to address this. Specifically, the interviewer may suggest the following additional conditions: there's a task to add one column (e.g. the city population size) and rename another (e.g. the specific province where this city is located).
At this point, the interviewer is evaluating the candidate’s ability to work with the database in a backward-compatible way. A candidate lacking experience in the migration of databases and schemes is likely to simply rename or add a column. Doing so will cause issues with compatibility, since the renamed column won't be accessible to the older version of the application. The candidate will be asked to come up with a recovery plan. An expected answer here: if you want to rename something, add a new column and keep the old one for several versions in a row, after which you can delete it.
Similarly, if we add a new column, we don't delete these updates if we need to roll back to the previous version, since we need to return to the later version of the application at some point.
-
How would you design tables to store the inheritance structure?
A candidate might also be asked to design tables to store the inheritance structure, like a person as a student and professor. Some of the fields are the same, some differ. There are multiple ways to handle that, each having its pros and cons. In brief, you can either have one table with a discriminator, or multiple tables.
-
[ ] ACID
-
[ ] Join
-
[ ] Transactions
-
[ ]
-
What is CAP theorem?
-
Why CAP theorem is obsolete? Is it?
-
What is RAFT? How does it solve the problem?
-
What is ACID? Is it still a thing?
-
What is eventual consistency?
-
Is the use of GUID as IDs a good practice?
-
What is sharding?
-
What is partitioning?
-
How to design a good partitioning?
-
What is an index? Clustered/Non-clustered?
-
How much clustered indexes might be? What is clustered index physically? What kind of data structures could be used for indexes? Why index lookups are fast? Is clustered index faster than non-clustered? Why?
-
Explain the difference between index seek and index scan
-
What is column-store index? When would you use it?
-
How can databases be replicated?
-
What is cold data and hot data?
-
How would you migrate an application from one database to another, for example from MySQL to PostgreSQL? If you had to manage that project, which issues would you expect to face?
-
What is lazy loading? What are the drawbacks of this approach?
-
How to find the most expensive queries in an application? How to monitor your database health and load?
-
What are database normalization rules? Is it acceptable to have denormalized database? If so, in which cases?
-
How to do blue-green deployments including database?
-
How NoSQL databases scale? How SQL databases scale?
-
When to use NoSQL and when to use SQL?
-
https://www.geeksforgeeks.org/explain-in-sql/
-
[ ] https://www.youtube.com/watch?v=N-4prIh7t38
Let's talk about data. You’ll need to know both traditional SQL databases (we love Postgres) and different types of NoSQL datastores (Redis, Cassandra, DynamoDB etc.). Work to understand Message Queues (Kafka, Kinesis) and Big Data engines (Spark, Storm, Flink).
[!info] Essential SQL Interview Questions | Toptal®
Know what to ask.
https://www.toptal.com/sql/interview-questions?utm_source=pocket_saves
-
[ ] JDBC
Data storage / Data model design
-
Indexing, partitioning, CAP(PACELC), normalization vs denormalization
-
NoSQL: types and use cases
-
JPA
-
[ ] Hibernate
[!info] Top 50+ Hibernate Interview Questions and Answers (2023)
Check out the most important Hibernate interview questions with detailed answers for freshers, intermediate and experienced candidates.
https://www.adaface.com/blog/hibernate-interview-questions/ -
[ ] Entity Manager
-
[ ] Persistance Context
-
-
What is an ORM? Why is it useful and why not?
Testing
-
What is a testing pyramid?
The testing pyramid is a model that categorizes software testing into three forms. This assists quality assurance and development experts in ensuring improved quality, reducing the time required to uncover the underlying cause of errors, and developing a more dependable testing system.
There are three layers in the testing pyramid. The pyramid's base is used for unit testing, the middle stage is used for integration testing, and the top and final layer is for user interface and exploratory testing.
-
Explain the process of end-to-end testing
End-to-end testing is a software testing approach that evaluates the complete software from start to finish, including its integration with other interfaces.
End-to-end testing considers the complete software for dependencies, data integrity, and connectivity with other systems, databases, and interfaces to simulate a complete production environment.
It checks batch and data processing from various upstream and downstream systems and the software system, which is how the approach gets the name "end-to-end." End-to-end testing is often performed following functional and system testing.
It simulates real-time conditions by using genuine production data and a testing environment. End-to-end testing is also known as chain testing.
-
What are the benefits of TDD over BDD?
Test Driven Development (TDD) and Behavior Driven Development (BDD) have their own merits and demerits. When comparing the two, TDD beats BDD when it comes to:
- Projects that involve API and third-party tools
- Projects that are meant to reduce the likelihood of finding bugs during testing
- Projects where tests have to satisfy just the developer and their code, in contrast to BDD, where the tests have to satisfy both the developer and customer
-
[ ] ==Mockito==
-
==JUnit==
-
==TestNg==
-
==Rest Assured==
-
[ ] ATDD
-
[ ] BDD
-
Think about testing and know how to write testable code. You’ll be expected to know how to write readable tests, using the appropriate level of abstraction ( Hamcrest, JsonAssert, etc.), and which corner cases to cover in your tests (@Parameterized runner, property testing). Understand what to mock and how, as well as knowing about the testing pyramid and common approaches in testing (TDD, BDD etc.).
-
What is a unit test? Academic definition vs real world definition
-
What is the difference between unit/integration/automated test? Discuss examples
-
What is TDD?
-
What is BDD?
-
What is performance testing?
-
What is load testing?
-
What is smoke testing?
-
What is regression testing? Is that correct that benchmarking is a part of the regression testing process?
-
What is chaos testing?
-
Why in TDD are tests written before code?
-
How to test a distributed system? Which types of test will you write? Which instruments would you use?
-
What is a test pyramid?
Infrastructure
CI/CD
- Continuous integration is used to automate your builds. It is the practice of swiftly and frequently merging code modifications into the main pipeline. CI is the foundation of a build process that is predictable, reliable, and always accessible. With CI, revisions are confirmed by generating a build and running automated tests against it to avoid bugs and issues that can emerge if all changes are merged into the release branch on release day.
- Continuous delivery augments continuous integration by automatically releasing any code changes following the build step to the test environment. This implies that, in addition to automated testing, you have an automatic release procedure and can deploy your application anytime by just pressing a button.
- Continuous deployment is a step beyond continuous delivery. Every update that makes it through all phases of your development pipeline is distributed to your consumers using this method. There is no human interaction; only a failing test precludes a new modification from going into production. Continuous deployment is a fantastic technique to shorten the feedback system with your clients and relieve strain on the team because there is no longer a fixed release day.
What deployment strategies have you worked with?
- Basic
- Multi-service
- Rolling/Ramped
- Blue-Green
- Canary
- A/B testing
- Recreate (Highlander)
- Shadow
Configuration Management Tools
What software configuration management tools have you used?
We use k8s with helm and argocd. We change configuration file and when changes are commited gitlab ci job deploys them to the environment
Jenkins
Networking
-
What are the OSI model layers?
The Open Systems Interconnection (OSI) model layers are:
- Physical, transmitting raw bit data over a physical medium
- Data Link, defining the data format
- Network, defining the physical path for the data
- Transport, transmitting data using protocols
- Session, responsible for ports and sessions control
- Presentation, displaying data in a usable format
- Application, enabling human-computer interaction
Containerisation
Docker
K8s
Message Brockers
Kafka
General
- How testing frameworks such as xUnit & NUnit know what methods to run?
- What is the most interesting thing you've made?
- What is Docker?
- How Dockerfile relates to Docker image layers?
- What is Kubernetes?
- What happens when you run
kubectl run --image=nginx --replicas=3? - What is blue-green deployment?
- What is CanaryRelease?
- What is the concept of infrastructure as code?
- What is the difference between authorization and authentication?
- What is .NET standard?
- What is merge and rebase, the difference between them?
- Git hooks
- Git reset, revert, checkout
- What is the difference between Mongo and Redis?
- What is the difference between queue and topic in messaging systems?
- What is REST? RESTful?
- What is idempotency? in terms of HTTP and/or messaging
- What is RPC? What are the general pitfalls of RPC?
- What is gRPC? When it could be useful?
- What is the difference between RPC and gRPC?
- What is SOAP?
- What is HATEOAS?
- What is HAL?
- What is eventual consistency? BASE?
- What is reactive programming?
- What is tail recursion?
- What is cyclomatic complexity?
- Public API versioning, how to do that right.
- What is feature toggling/flagging? 1(https://www.youtube.com/watch?v=7qTOdbUAqno) [2](2)(https://www.pluralsight.com/courses/dotnet-featuretoggle-implementing) [D2_BE_Interview](.md)
- What happens when you type 'google.com' into the browser address bar and press Enter?
- What is public IP, private IP? NAT? IPv4? IPv6? 0(https://www.digitalocean.com/community/tutorials/understanding-ip-addresses-subnets-and-cidr-notation-for-networking) [1](1)(https://www.digitalocean.com/community/tutorials/an-introduction-to-networking-terminology-interfaces-and-protocols)
- Explain event hub over service bus, consumer groups and other concepts related.
- What is partitioned consumer pattern? Competing Consumer?
- What is tracing, spans, opentracing?
- What is ELK stack?
- What is structured logging? Does it have any advantages over plaintext logging?
- Why does array index start with '0' in most languages?
- What are dynamic- and static-typed languages? Which one to pick for developing enterprise software? Explain your thoughts.
- What is overengineering? How can it affect enterprise software in the short run and in the long run?
- What is the difference between pattern matching and just a switch clause?
- Pretend you have a time machine and pretend that you have the opportunity to go to a particular point in time during Java's (or C#, Python, Go or whatever) history, and talk with some of the JDK architects. What would you try to convince them of? Removing checked exceptions? Adding unsigned primitives? Adding multiple-inheritance?
- How to explain legacy code to non-technical person e.g. Project Manager or Product Owner? Why it's important to care about legacy code? How would you deal with legacy code?
- When to use cache? When it can be not useful or even dangerous?
- I want to refactor a legacy system. You want to rewrite it from scratch. Argument. Then, switch our roles.
- What is GOTO statement? What's wrong with it? Do we still have GOTO statements or something similar to them in modern programming languages?
- What is monorepo and what is multirepo? When it's better to chose one over another? 0(https://medium.com/@adamhjk/monorepo-please-do-3657e08a4b70) [1](1)(https://medium.com/@mattklein123/monorepos-please-dont-e9a279be011b)
- Tell me about your favorite language/framework. Is it really that good? Does it have any weaknesses?
Practical
class Person {
Gender gender;
String name;
public Gender getGender() {
return gender;
}
public String getName() {
return name;
}
}
enum Gender {MALE, FEMALE, OTHER}
//Get the list of uppercase names of all the “FEMALE” people in the list of persons.
public List<String> getFemaleNames(List<Person> persons){
List<String> femaleNames = new ArrayList<>();
if(persons!=null){
filteredPersonCollection = personCollection.stream()
.filter(person -> person!=null && person.getName() !=null && Gender.FEMALE == person.getGender())
.map(person -> person.getName().toUpperCase())
.collect(Collectors.toList());
}
return femaleNames;
}
Management
-
How do you approach project estimations?
A well-designed project estimation will include an outline of the tasks involved, resources required, cost rate, project duration, and any required third-party services. Several strategies are available, including the bottom-up, three-point, parametric, and analogous estimation methods.
With your answer, you’ll want to outline the approach or approaches you traditionally use. Discuss projects where you applied the methods and discuss the results to showcase the effectiveness of your strategy.
-
Name the stages of the software development lifecycle (SDLC)
The stages of the software development life cycle are:
- Planning
- Requirements gathering and analysis
- Design
- Coding and implementation
- Testing
- Deployment
- Maintenance
Like the question above, this one tests your knowledge. As long as you outline the stages, that’s usually sufficient.
-
Compare waterfall and agile models and provide examples of their use cases
The waterfall methodology is a sequential process where tasks are handled in a linear fashion. Generally, it’s best used when the requirements are clear, well-known, and entirely fixed.
The agile methodology uses an iterative process that relies on cyclic patterns with a high degree of collaboration. Agile provides ample room for feedback and future adjustments, making it a better fit in cases where goals and requirements may shift, or other unknowns are likely to arise.
With this answer, you can dive into examples from your past work to serve as use cases. That can add something extra to your response and may help you stand out.
-
When is it best to apply SAFe?
SAFe (Scaled Agile Framework) is usually best applied when:
- There are no other agility transformation efforts underway.
- You prefer genuine change over cosmetic changes.
- A release cycle of 10–12 weeks is appropriate.
- Hardware or other products with long lead times (up to 10 weeks) need to be integrated with items with shorter lead times.
- There is no desire to downsize the organization.
- There is no desire to create a Lean/Agile organization with solely Lean/Agile positions at various levels, such as Architecture Owner, Flow Manager, and Product Owner.
- Kanban is utilized at all levels because it is implemented at the team level.
- You want to enhance team performance, be comfortable, and be ready to become agile.
- DevOps is completely accepted, and test automation is an integral element of how the company operates.
- Everyone impacted by SAFe receives a formal SAFe® training. SAFe is documented, but mentality change is required, which may be accomplished through in-class instruction.
- Product Owners are completely empowered and no position undermines their function.
-
Name and explain Scrum roles
There are three main Scrum roles. They include:
- Scrum Master, ensuring that a Scrum team operates as efficiently as possible by following Scrum ideals, keeping the team on course, preparing and conducting meetings, and resolving any roadblocks that may arise.
- Scrum Product Owner, ensuring that the Scrum team is on the same page as the overarching product goals. They comprehend the product's commercial requirements, such as consumer expectations and industry trends.
- Development Team, comprising experts who do the work in a Scrum sprint on the ground. This implies that members of the development team span any skill set required to meet sprint objectives.
-
Have you ever had to introduce a new process at work? What approach did you take to gain cooperation?
Whatever it was you introduced, the methods of gaining cooperation tend to stay the same:
- Communicate clearly why the change is necessary.
- Have the backing of the leadership and key figures within the organization.
- Adapt the learning material to fit the employees’ needs.
- Use visual aids to help speed up the adoption of your new processes.
- Share any documentation where relevant or necessary.
- Make sure the employees don't feel pressured to succeed or fear failure.
-
Describe a situation where you successfully convinced others of your ideas
Whenever you have to convince others of an idea in a workplace, there are some steps to take:
- Do favors for others, especially when they do not ask much of you, and you’ll have willing listeners when you pitch ideas.
- Establish what your goals are, so others see something to focus on.
- Initiate a dialogue with the people most affected by changes the idea may bring.
- Use reliable sources to guide your idea.
- Prepare what you want to say or implement beforehand to grab your audience’s attention and keep it during your pitch.
- Show your audience what the outcome will be, so they have an incentive to want what you are suggesting.
-
Have you done user research? What kind?
- Quantitative research is generally exploratory and is used to define an issue by creating statistical data or data that can be converted into meaningful statistics. Online polls, paper questionnaires, mobile surveys, longitudinal studies, site interceptors, opinion surveys, and systematic observations are all frequent data gathering approaches.
- Qualitative user research is an observational examination of behavior. It's about getting to know people's ideas and practices on their own terms. Contextual observation, ethnographic research, interviews, field research, and controlled usability testing are some of the methodologies that might be used.
-
Have you ever had to make a high-impact decision? How did you handle it?
To handle high-impact decisions, you have to include everyone who will be affected by the changes you make. That is why when you are about to make a high-impact decision, you need to make sure you:
- Identify and define the context and constraints.
- Present at least two solutions, to avoid falling victim to the law of instrument bias.
- Log every decision made and all relevant data surrounding it to ensure that you can always identify why you made a change and how you made it.
- Hold meetings or talks with everyone involved to get feedback on what you would like to implement.
After all that, you can document the changes, implement them, and communicate relevant information to the involved parties.
Frontend
- [ ]
- [ ] https://www.linkedin.com/learning/paths/explore-react-js-development?u=2113185
- [ ] https://www.educative.io/answers/how-to-create-a-react-application-with-webpack
[!info] React Developer Roadmap: Learn to become a React developer
Community driven, articles, resources, guides, interview questions, quizzes for react development.
https://roadmap.sh/react
[!info] JavaScript Developer Roadmap: Step by step guide to learn JavaScript
Community driven, articles, resources, guides, interview questions, quizzes for javascript development.
https://roadmap.sh/javascript
[!info] Full Stack Developer Roadmap
Learn to become a modern full stack developer using this roadmap.
https://roadmap.sh/full-stack
Questions
When to use composition, when inheritance
What is the point of static and default methods in interface?
What will happin if we inherit interfaces with the same default methods
How many threads are created for parallel streams?
Number of CPU cores
Distinct by id in stream
Function<Function<Car,Long>,Predicate<Car>> distinctById = (keyExtractor) -> {
Set<Object> seen = new HashSet<>();
return item -> seen.add(keyExtractor.apply(item));
};
timecardChanges.stream()
.filter(distinctById.apply(change -> change.getId()))
.collect(Collectors.toList());